
内存管理的基础内容可以看另一篇博客:内存管理篇
VMSA
MMU
VMSA 提供了 MMU 硬件单元,MMU 中还包含了 TLB,保留的是 MMU 页表翻译后的转换结果。
MMU 硬件单元用来实现 VA 到 PA 的地址转换(转换由硬件自动转换):
- 硬件遍历页表:table walk
- TTBR0/1:页表基地址寄存器,指向当前使用的页表(一级页表)的物理地址
其中,TTBR0 通常用于用户空间地址转换,TTBR1 用于内核空间地址转换。为了实现用户态和内核态进程的隔离,保证内核空间不被用户空间访问,因此可以看到我们总线有 64 bit,但实际上用户空间和内核空间的地址范围都被限制在 48 bit 内,原因是这样就可以通过 TTBR0 和 TTBR1 分别指向不同的页表来实现用户空间和内核空间的地址转换。
- 内核空间:0xFFFF000000000000 ~ 0xFFFFFFFFFFFFFFFF,占用高位虚拟地址空间
- 用户空间:0x0000000000000000 ~ 0x0000FFFFFFFFFFFF,占用低位虚拟地址空间
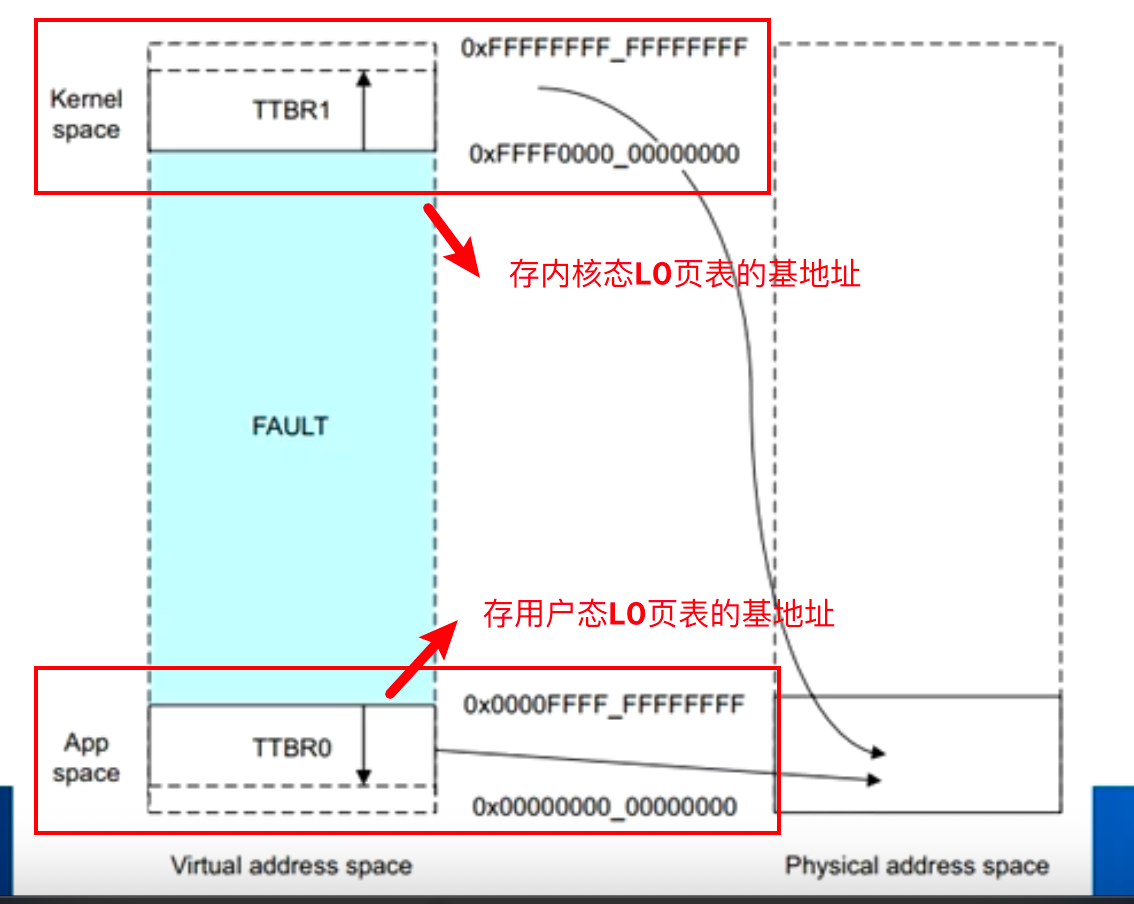
硬件单元的作用:
- 地址转换:将虚拟地址转换为物理地址
- 权限检查:根据页表项中的权限位检查访问权限
- 内存属性检查:根据页表项中的内存属性位检查访问类型(如缓存策略)
页表描述符
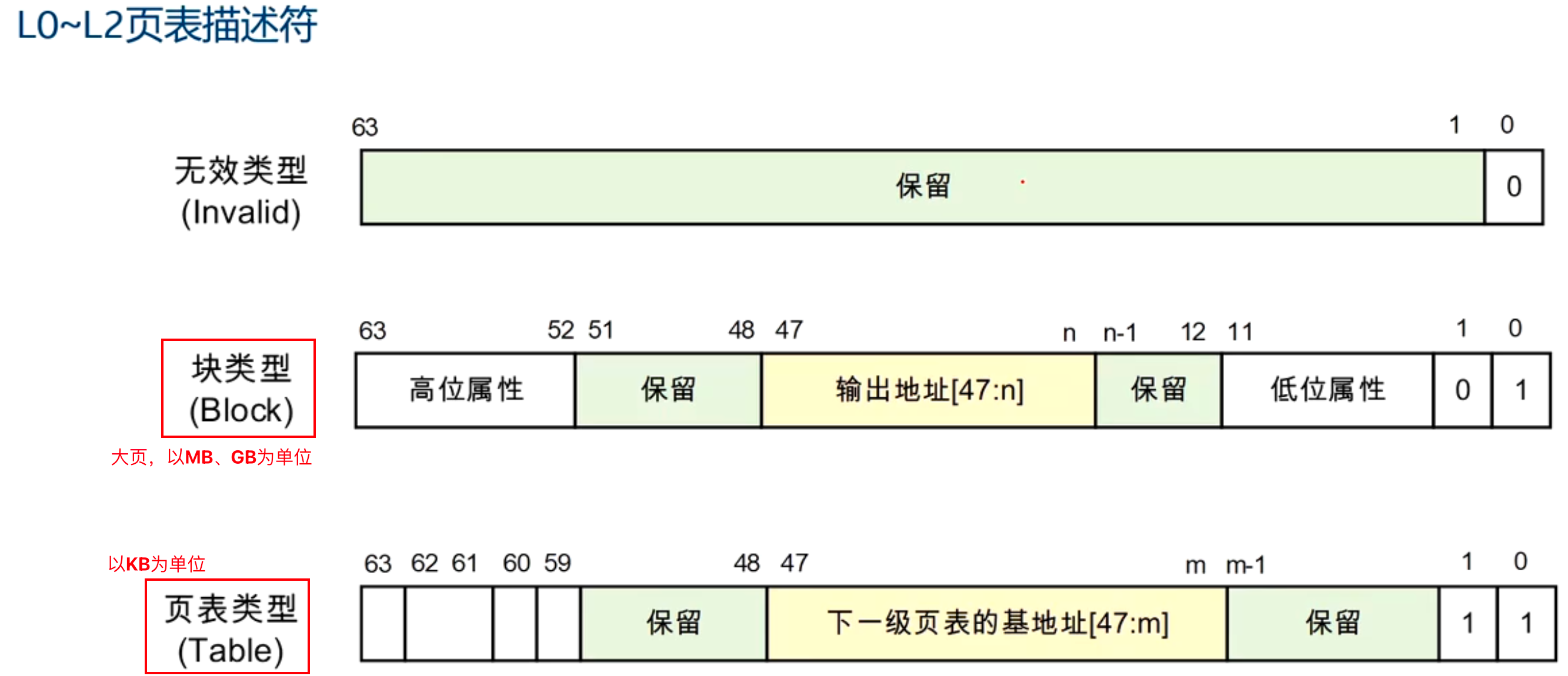
L0-L2页表描述符有三种类型:
- 无效页表项:表示该页表项无效,访问该页会触发页错误异常
- 块类型页表项:表示该页表项直接映射一个大页(如2MB或1GB),不需要继续遍历下一级页表
- 页表page table类型页表项:表示该页表项指向下一级页表(最常见)
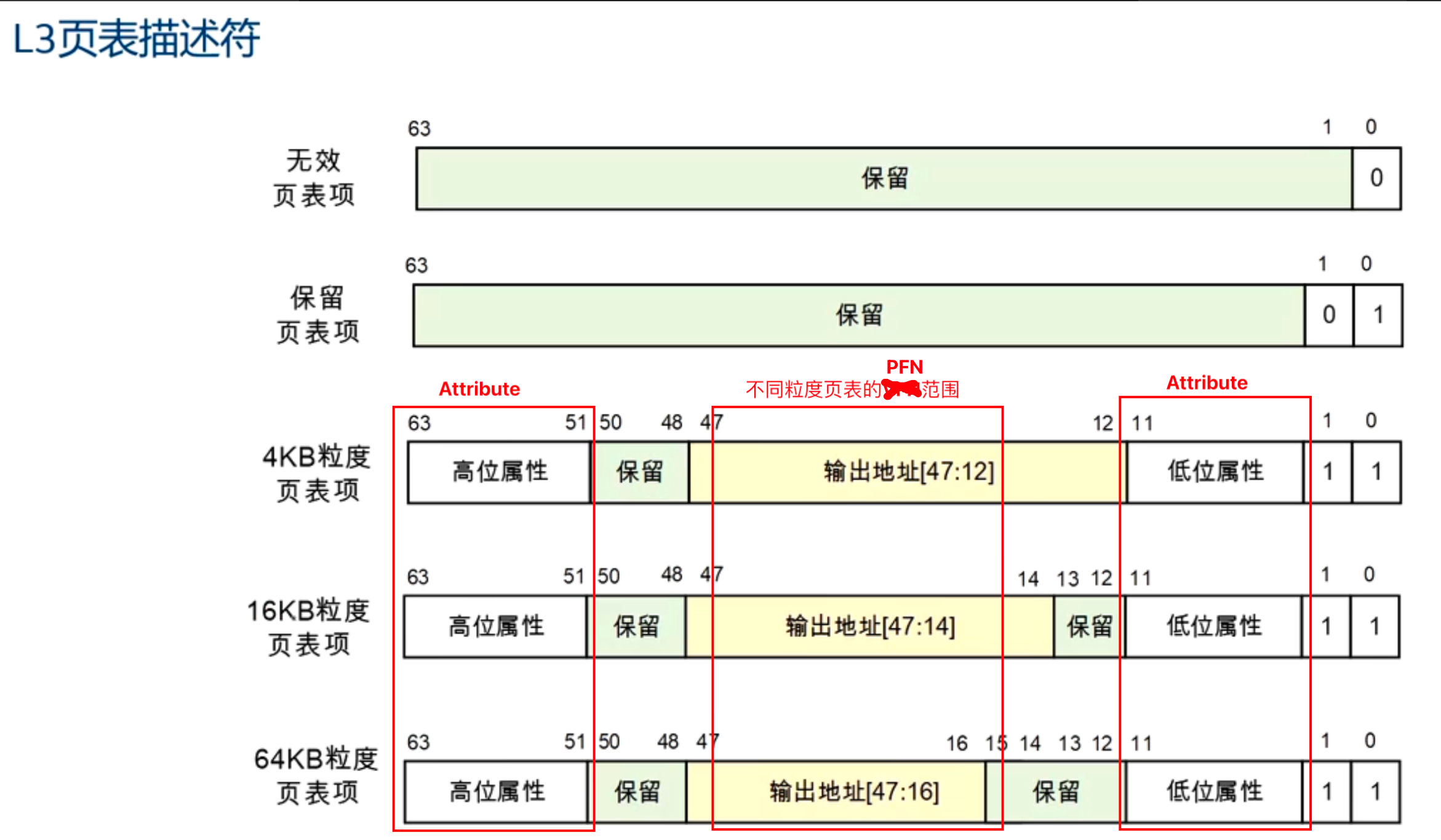
L3页表描述符有五种类型:
- 无效页表项:表示该页表项无效,访问该页会触发页错误异常
- 保留页表项:表示该页表项保留,访问该页会触发页错误异常
- 4KB粒度页表项:表示该页表项映射一个4KB的页
- 16KB粒度页表项:表示该页表项映射一个16KB的页
- 64KB粒度页表项:表示该页表项映射一个64KB的页
页表属性包含了该 entry 的读写权限位、访问位、脏位、内存属性位等信息,stage1的一些典型页表属性如下:
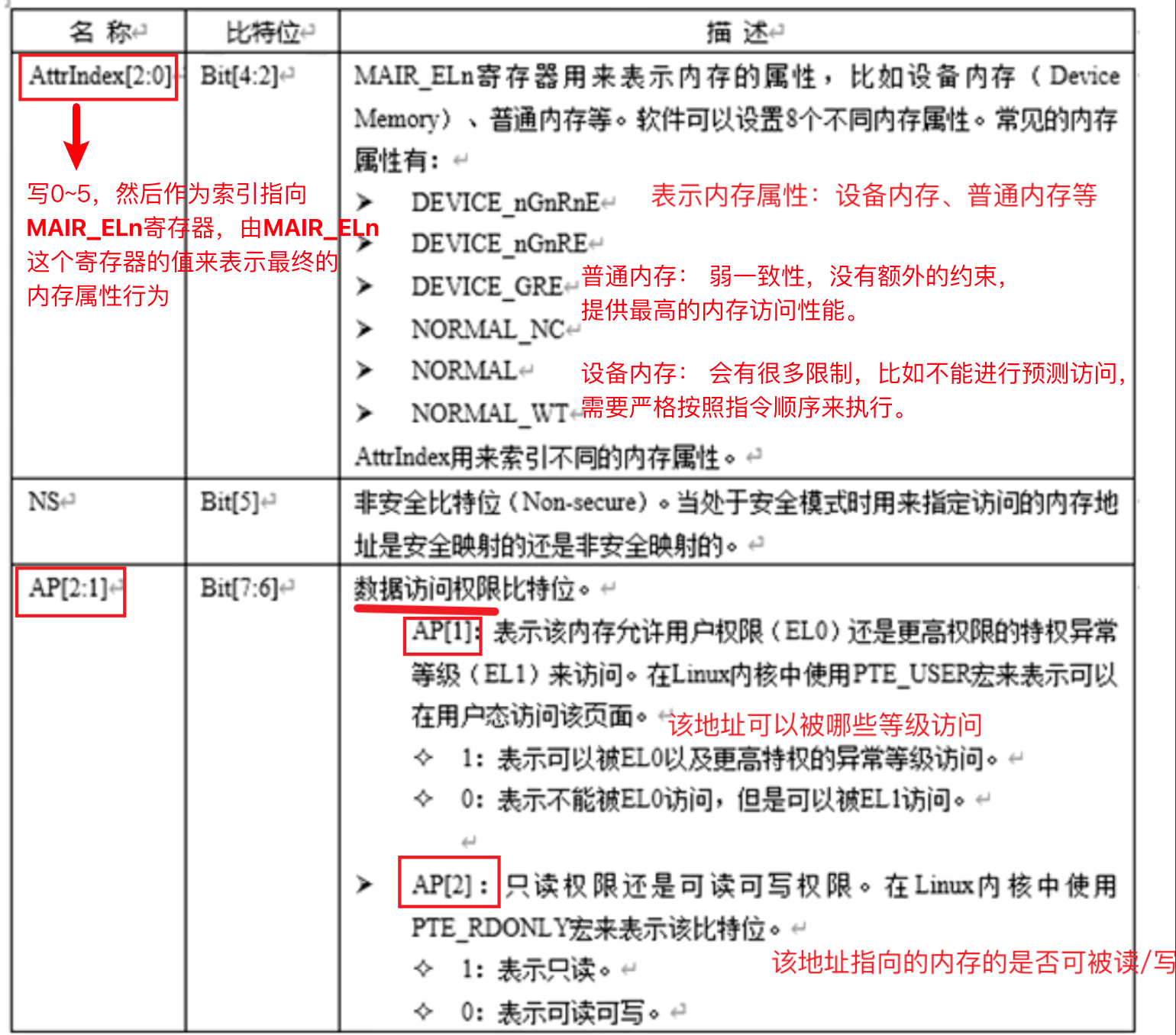
- Device-nGnRnE: 不支持聚合操作,不支持指令重排,不支持提前写应答。
- Device-nGnRE: 不支持聚合操作,不支持指令重排,支持提前写应答。
- Device-nGRE: 不支持聚合操作,支持指令重排,支持提前写应答。
- Device-GRE: 支持聚合操作,支持指令重排,支持提前写应答。
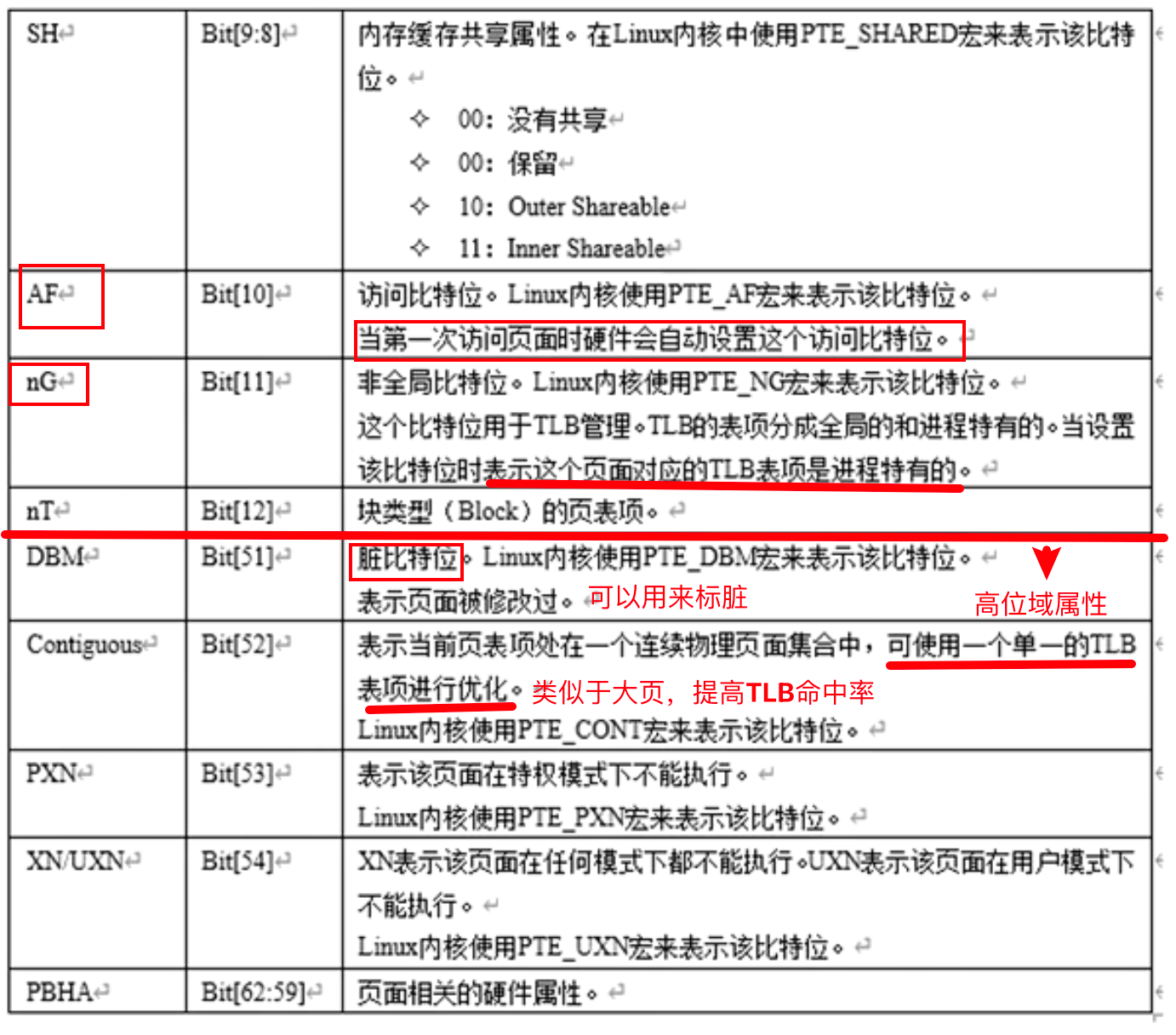
Armv8 上利用 TLB 进行的一个优化: 通过设置 Contiguous bit,利用一个 TLB entry 来完成多个连续 page 的 VA 到 PA 的转换。
使用 Contiguous bit 的条件: - 页面对应的 VA 必须是连续的
对于 4KB 的页面,16 个连续的 page
对于 16KB 的页面,32 或者 128 个连续的 page
对于 64KB 的页面,32 个连续的 page
连续的页面必须有相同的属性
起始地址必须以页面对齐
根据上述这些 Attribute 配置,在linux kernel中定义了一些代表 Attribute 集合属性的宏:
1 | //.linux/include/asm/pgtable-prot.h |
实验一:建立恒等映射:VA=PA
实际上多进程运行的系统中,我们不会用恒等映射,VA不会等于PA。但是某些特殊场景下是要求用恒等映射的。
我们知道,在MMU开启后,PC指令存的值也是虚拟地址,然后经过页表映射成物理地址后,在内存中查找对应的代码来执行。
但是在 MMU 初始化的过渡阶段,必须采用恒等映射,防止开启 MMU 前预取的指令在开启 MMU 后,被当做是虚拟地址,地址转换后导致访问异常。
MMU 初始化阶段之所以用恒等映射,是因为现代处理器是多级流水线架构,在使能 MMU 前,处理器会用物理地址来预取多条指令。
- PC 中的值直接是物理地址
- CPU 使用 PC 的值直接从物理内存取指令
- 没有地址转换
- eg:
PC = 0x80000 → 直接读取物理地址 0x80000 处的指令
但是当 MMU 打开后,之前预取的指令会以虚拟地址来访问,到 MMU 中查找对应的物理地址,因此,这里恒等映射是为了保证处理器在开启 MMU 前后可以连续取指令。
- PC 中的值是虚拟地址
- CPU 需要通过 MMU 将虚拟地址转换为物理地址
- 查询页表 (PGD→PUD→PMD→PTE) 获取物理地址
- eg:
PC = 0x80000 → MMU查询页表 → 物理地址 0x80000 → 读取指令,可以看到,恒等映射的话,能确保之前预取的 PC 值经过页表转换后依然不变,这样才能正常访问。
一般来说,为了防止访问失败,一般在打开 MMU 的前后 1~2MB 建立恒等映射就行,这种操作称为自举。当然,我们实验中选择映射 512 MB 的恒等映射,也是为了能对这块区域进行测试,更方便观察。
实验原理是,只对前 512 MB 的内存建立恒等映射,后面的不建立页表,这样的话就可以写一个 test case 来验证前 512 MB 的内存访问是正常的(0x00000000~0x1FFFFFFF),而访问超过 512 MB 的内存会触发页错误异常。来验证我们建立的页表映射是正确的。
1 | 512MB = 2^29 bytes = 0x20000000 bytes |
每个页的地址范围(512MB / 4KB = 131,072 个页):
| 页号 | 起始地址 | 结束地址 |
|---|---|---|
| 0 | 0x00000000 | 0x00000FFF |
| 1 | 0x00001000 | 0x00001FFF |
| 2 | 0x00002000 | 0x00002FFF |
| ... | ... | ... |
| 131,071 | 0x1FFFF000 | 0x1FFFFFFF |
一、创建页表
各级页表的大小是固定的,也就是PAGE_SIZE = 4KB,四级页表中,每级的页的
entry 大小都是 8 bytes(64位,存下一级的基地址),每一页都是 4
KB,所以每一页的页表项 entry 数量是固定的:
1 | entry 数量 = 页面大小 / 每个 entry 的大小 |
其中每个 entry(页表项)的大小是 8 bytes(64位),存储物理地址的高位和标志位。512个 entry 正好填满一个 4KB 页面。
创建 4 KB 页表的代码为:
1 | static unsigned long early_pgtable_alloc(void) |
创建 PGD 页表 && 实现映射
创建页表时会先创建 text 段映射,原因是:CPU 正在执行的代码就在 text 段中,启用 MMU 后,CPU 的下一条指令地址必须在页表中已存在,否则会立即触发页错误导致崩溃。这就是自包含代码的自举问题。早期初始化阶段,只需要确保代码段能继续执行(ROX),其他数据段、栈等可以在后面逐步映射。
ELF 文件中的段:
| 段名 | 含义 | 权限 |
|---|---|---|
| .text | 代码段(可执行的机器指令) | R + X(可读+可执行) |
| .data | 已初始化数据段(全局变量) | R + W(可读+可写) |
| .bss | 未初始化数据段 | R + W |
| .rodata | 只读数据段(字符串常量等) | R(只读) |
在链接脚本./src/linker.ld中,_text_boot和_etext分别是
text 段的起始地址和结束地址,链接器会根据这些符号来确定 text
段在内存中的位置和大小。
1 | SECTIONS |
大小来源:代码段大小(_etext - _text)不是手动定义的,而是由编译器和链接器自动计算。编译器将每个
.c 文件编译成 .o 文件时生成 .text
段,链接器在链接时把所有 .text
段收集并连续排列,最终形成完整的代码段。_text 和
_etext
之间的内容就是所有函数编译后的机器指令,包括内核代码、启动代码等。
这种设计让代码段大小自动适应代码规模。当添加或删除代码时,编译器会自动调整
.text 段大小,链接器会更新 _etext
的值,映射代码不需要手动修改。这样既保证了正确性,又提高了可维护性。
创建 text 映射的代码如下:
1 | static void create_identical_mapping(void) |
用 gdb 查看你 start 和 end 的值,就可以算出 text 段大小:
1 | (gdb) p/x start |
之后就会在创建 text 的时候,顺便把 pgd 页表创建了,并逐级创建 text 字段的页表:
1 | /** |
其中,pdg entry可能是没有填充下一级 pud 页基地址拼接起来的 64 位
entry值的,因此该 entry 的填充会在alloc_init_pud
函数中完成,创建完一个 pud 页后,就可以拿到pud
页的基地址,也就可以填充给 pgd entry 了。填充规则如下图所示:
创建 PUD 页表 && 实现映射
如果上一级 pgd entry pgd_t *pgdp 指向的 pud
页不存在,才会创建一个 pud 页并填充到 pgd entry 中。否则会直接映射下一级
pmd 页表。
pud 页的创建是通过从上一级页表 pgd entry 指针中获取 entry 里的 64 位数据,这 64 位数据可以提取出 pud 页的基地址,然后根据 va 提取的 pud 页 index 索引拼接获取下一级 pud entry 的物理地址。
然后再映射到下一级 pmd 页表中alloc_init_pmd。
1 | /** |
创建 PMD 页表 && 实现映射
PMD 页表的创建跟创建 PUD
页表一样,只是在映射下一级页表的逻辑中有所差异,因为内存分为块类型页表项和页表page
table类型页表项,如果是块类型页表项,则直接调用pmd_set_section函数,没有下一级
PTE 页表了,否则调用alloc_init_pte函数创建下一级 PTE
页表。
1 | void pmd_set_section(pmd_t *pmdp, unsigned long phys, |
代码跑到 alloc_init_pmd 函数中,我们 gdb 打断点查看一下它的 flags 值:
1 | (gdb) p flags |
发现我们前面 create 的内存的属性全部都是0,而
NO_BLOCK_MAPPINGS 值是1。所以全部会走 PTE
create 逻辑,创建 PTE 页表。
创建 PTE 页表 && 实现映射
最后一级 PTE 的映射就很简单了,只用把 PFN 值填到 PTE entry 中就行了
1 | static void alloc_init_pte(pmd_t *pmdp, unsigned long addr, |
还要注意一下 set_pte 的填充协议跟
L0~L2级别页表不一样:
二、初始化 MMU
要注意,页表修改后,需要把相关的 TLB entry 刷新掉,否则可能会访问到过期的 TLB entry 导致访问错误。
初始化 MMU 的时候需要做的事:
- 初始化 PGD 页表目录:清空 PGD 页,准备好页表基地址(idmap_pg_dir)
- 创建代码段(.text)映射:建立恒等映射(VA=PA),确保启用 MMU 后代码能继续执行
- 创建测试内存映射:建立 512MB 内存的页表映射,用于测试页表功能
- 创建 MMIO 映射:为设备寄存器区域建立映射,使用设备内存属性
- 配置 CPU MMU 寄存器:设置内存属性(MAIR)、虚拟/物理地址范围(TCR)、浮点支持等
- 启用 MMU:设置页表基地址(TTBR0),使能 MMU(SCTLR_EL1.M),刷新 TLB
1 | void paging_init(void) |
三、访问测试
该测试中,需要创建完 text 内存映射后,再创建 512MB 的内存映射:
1 | static void create_identical_mapping(void) |
代码中只设置了代码段~512MB的内存,因此先测试创建的内存以内的地址访问会触发页错误异常(TOTAL_MEMORY - 4096),然后测试没有内存映射的地址访问会触发页错误异常:
1 | static int test_access_map_address(void) |
最后的运行结果如下:
1 | akira@akira:~/BenOS/BenOS_ARM/benos$ make run |
实验二:dump 页表
我们 debug 内存相关的内容的时候,经常需要 dump 出页表的虚拟地址、页表项属性等信息。
同时,这也可以看出我们的页表映射是否正确。
实现方法是软件上遍历页表,遍历到页表的叶子节点时,打印出虚拟地址、页表项属性等信息。
一、定义打印内容-数据结构
需要打印的内容: - 页表项属性对应的属性值(转成文字描述) - 叶子节点的层级:pg_level[].name = PGD/PUD/PMD/PTE - 每个叶子节点 entry 代表的页面大小 - 普通内存页是 4K,叶子节点的层级是PTE - 大页有可能是是 2MB,叶子节点的层级是PMD
1 | struct prot_bits { |
下面在初始化 MMU 后,就可以初始化一下各个层级的各个属性的mask值,把所有属性位全部置为1:
1 | static void pg_level_init() |
运行结果如下:
1 | (gdb) p/x pg_level[1].mask |
二、遍历页表并打印
遍历页表的逻辑跟创建页表的类似,也是一层一层遍历下去,这里就不赘述了。唯一不一样的是遇到PUD_TYPE_SECT/PMD_TYPE_SECT/PTE_TYPE_SECT属性时,表示是叶子节点,此时停止遍历,调用print_pgtabledump
打印节点信息。
1 | walk_pgd |
1 | static void walk_pud(pgd_t *pgdp, unsigned long start, unsigned long end) |
运行结果如下:
create_identical_mapping函数创建出来的.text 段不是 2MB 对齐的,虽然设置了BLOCK_MAPPINGS但是非 2MB 对齐,因此也是创建 PTE 节点:1
2
3
4
5
6
7
8---[ Identical mapping ]---
0x0000000000080000-0x0000000000081000 4K PTE ro x SHD AF UXN MEM/NORMAL
0x0000000000081000-0x0000000000082000 4K PTE ro x SHD AF UXN MEM/NORMAL
0x0000000000082000-0x0000000000083000 4K PTE ro x SHD AF UXN MEM/NORMAL
...
0x00000000001fd000-0x00000000001fe000 4K PTE RW NX SHD AF UXN MEM/NORMAL
0x00000000001fe000-0x00000000001ff000 4K PTE RW NX SHD AF UXN MEM/NORMAL
0x00000000001ff000-0x0000000000200000 4K PTE RW NX SHD AF UXN MEM/NORMALcreate_identical_mapping函数创建出来的 512MB 块内存区域:1
2
3
4
5
6
70x0000000000200000-0x0000000000400000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0x0000000000400000-0x0000000000600000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0x0000000000600000-0x0000000000800000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
...
0x000000001fa00000-0x000000001fc00000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0x000000001fc00000-0x000000001fe00000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
0x000000001fe00000-0x0000000020000000 2M PMD RW NX SHD AF BLK UXN MEM/NORMAL
非 text
段的普通内存页范围为0x86000~0x20000000,所以也有一部分未对齐的普通内存页被写成
4KB 内存了。原因是:
1 | _etext = 0x850d0 |
0x86000 不是 2MB 对齐的,因此会创建 4KB 页节点
1 | python3 -c "print(hex(0x86000 % 0x200000))" |
所以从 0x86000 开始:
- 先用 4KB 页填充到 0x90000(下一个 2MB 边界)
- 从 0x200000 开始才是 2MB 对齐,才用 2MB 块
1 | 0x86000 ──── 4KB 页 ───→ 0x200000 ──── 2MB 块 ───→ 0x20000000 |
不同内存区域的对齐方式导致 dump_pgtable 会同时看到 4KB 和 2MB 叶子节点:
| 内存区域 | 起始/结束对齐 | 结果 |
|---|---|---|
| .text 代码段 | 通常不是严格 2MB 对齐 | 4KB 页(PTE 叶子) |
| 512MB 内存 | 通常是 2MB 对齐 | 2MB 块(PMD 叶子) |