
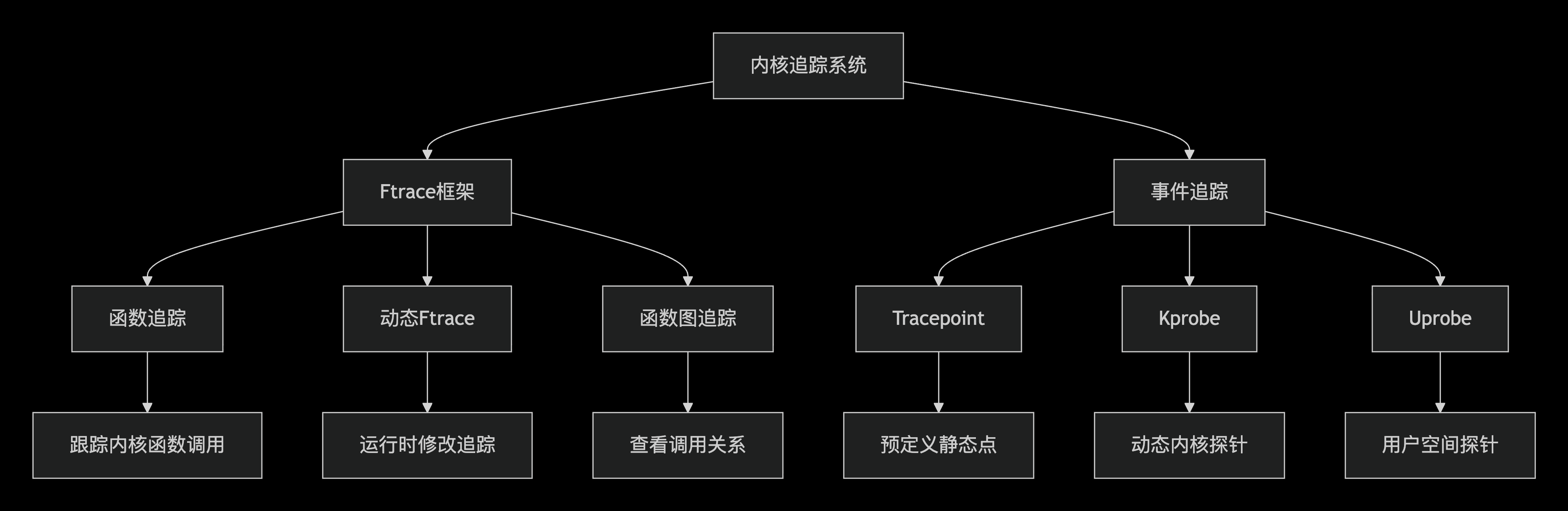
当我们需要查看内核中函数是否调用、入参值是否符合预期、函数返回值、函数调用栈等问题时,我们可以在启动机器后,通过trace方法来动态获取这些信息。
ftrace是最常用的工具,其中kprobe和tracepoint是其中的两个子工具。
通用操作
过滤
如果要过滤的话,可以查看该函数的format才能知道怎么过滤:
1 | cat events/目录/函数名/format |
然后就可以根据format中的字段来过滤:
1 | echo 'irq==123' > events/irq/irq_handler_entry/filter |
查看有哪些可用的 trace events
查看的是包括 tracepoint 和 kprobe 在内的所有 trace
事件,说白了,kprobe 事件也是 trace event
的一种。所以我们| grep kprobe就能看到所有的 kprobe
事件,跟我们平时| grep kvm看到的某个子模块 (kvm)
事件是一样的。
1 | cat available_events | grep kprobe |
set_event 设置跟踪的事件
1 | echo 'kvm:kvm_exit' > set_event |
kprobe
内核中几乎所有函数都可以被kprobe拦截,包括内核初始化时的函数。kprobe可以用来跟踪函数的调用、入参值和返回值,且不需要手动写trace代码。
cd /sys/kernel/debug/tracing
查看
查看所有kprobe可用的函数(几乎所有内核函数都在available_filter_functions中):
1 | cat available_filter_functions | grep __setup_irq |
当前已经添加跟踪的事件:
1 | cat kprobe_events |
禁用所有已存在的 kprobe 事件
1 | 禁用所有已存在的 kprobe 事件(关键步骤) |
进行一些清除操作
1 | echo nop > current_tracer |
添加 kprobe 事件到 kprobe_events
原生tracing目录下是没有events/kprobes/目录的,但是为了方便管理
kprobe 事件,我们可以把 kprobe
事件都添加到events/kprobes/目录下进行管理。(echo
命令里带不带 kprobes 都会被定向到kprobes文件夹中)
添加的事项可以有 p 标志的和 r标志的,其中
r标志的表示跟踪的是这个函数的返回值
1 | echo 'p:kprobes/p___setup_irq __setup_irq irq=%x0 desc=%x1 new=%x2' > kprobe_events |
其中可以根据参数类型来选择不同的格式化输出:
1 | echo 'p:vfio_pci_set_msi_trigger vfio_pci_set_msi_trigger type=%x1:u32 count=%x3:u32 flags=%x4:u32' > kprobe_events |
参数类型:
:x8-64:表示 8-64 位十六进制数:s8-64:表示 8-64 位有符号十进制数:u8-64:表示 8-64 位无符号十:string:表示字符串
寄存器参数:寄存器一般是通用寄存器,在 ARM64 架构中,参数传递通常使用
x0 ~ x7 寄存器,按照传入参数顺序依次为 -
第一个参数:%x0 - 第二个参数:%x1 - ...
所以我们一般要求函数参数控制在 5 个以内,如果函数参数超过了寄存器的数量,额外的参数通常会通过 栈 或 其他寄存器 传递。
查找对应偏移量的方法:
1 | way 1 |
偏移量的获取参考Kernel调试追踪技术之 Kprobe on ARM64
过滤、禁止输出调用栈
1 | echo 'name=="eth2"' > events/kprobes/filter # 过滤入参 name==eth2 的事件 |
启动追踪
1 | echo 1 > events/kprobes/enable # 启用所有 kprobe 事件 |
查看输出
1 | cat trace # 可以看到所有的 trace,包括耗时 |
停止追踪
1 | echo '-:p___setup_irq' > kprobe_events # 删除某个 kprobe 事件 |
清空缓存
1 | echo > trace |
示例:使用 kprobe
跟踪__setup_irq
用 kprobe 查看__setup_irq:
1 | cd /sys/kernel/debug/tracing |
tracepoint 内核插桩
其优点是可以按照我们预期地输出信息,且可以替代printk。缺点是需要内核源码中明确定义
tracepoint 事件,且无法像 kprobe
通过echo 'name=="eth2"' > events/kprobes/filter来过滤特定
pid 的 tracepoint 事件,需要在桩函数代码中自己实现过滤。
trace point 是内核中预定义的跟踪点,通常用于跟踪内核事件。与 kprobe 不同,tracepoint 需要内核源码中明确定义。并显式调用 tracepoint 事件。
有时我们需要printk来输出信息,但printk的输出量很大,且无法控制输出格式。而
tracepoint 可以通过 ftrace 来控制输出,且输出格式可以自定义。
tracepoint都有一个 name、一个 enable
开关和一系列桩函数。
tracepoint 结构体
在./include/linux/tracepoint-defs.h中提供了tracepoint struct结构体来定义
tracepoint 的信息。
1 | struct tracepoint { |
创建 tracepoint
内核里已经自带实现了许多 tracepoint
桩函数,可以在/sys/kernel/debug/tracing/events/目录下看到。
1 | root@akira:/sys/kernel/tracing# ls ./events/irq |
如果想实现添加自己的 tracepoint,可以参考下面的步骤:
首先要在内核中插件入 tracepoint,需要在内核源码中添加 tracepoint
的定义和实现。一般基于模块粒度创建一个trace头文件,本例中创建./include/trace/events/irq.。
比如对于irq,可以在./include/trace/events/irq.h中添加
tracepoint 定义:
1 | /* SPDX-License-Identifier: GPL-2.0 */ |
然后可以在./include/trace/events/irq.h中添加 tracepoint
的定义和实现,一个 tracepoint
文件可以包含多个事件,这里以irq_handler_exit为例:
1 | /** |
代码中调用 tracepoint
在内核代码中,可以通过trace_irq_handler_exit来调用
tracepoint。比如在./kernel/irq/handle.c中要调用这个
tracepoint 的话,添加对应的头文件:
1 |
注意!!如果是自己添加的 tracepoint 头文件,需要在第一次调用的文件里面加上:
1 |
且整个工程中关于同一个tracepoint 文件只能有一个文件定义这个宏,否则编译会不通过。正常情况下如果你没有重新自己创建一个 tracepoint 文件,只是在现有的 tracepoint 文件中添加事件的话,是不需要在调用处定义这个宏的。
然后使用的时候直接调用:
1 | trace_irq_handler_exit(irq, action, res); |
内核中动态查看相关桩函数的打印
查看可用的 tracepoint 以及它们的输出格式:
1 | 查看所有 irq 相关的 tracepoints |
启用和查看 tracepoint
1 | 方法1:单个启用 |
也可以使用 perf 工具来查看 tracepoint 的输出:
1 | 查看所有可用的 tracepoints |
trace_printk
在代码中可以直接通过trace_printk来输出信息,输出的信息会被
ftrace 捕获并显示在 trace
中。相比于printk,trace_printk的输出量更小,用法跟普通的printf类似,可以输出格式化字符串和变量值。
1 | trace_printk("This is a trace message with value: %d\n", value); |
但他不会输出到内核日志中,所以不会对系统性能产生太大影响,且可以通过 ftrace 来控制输出的格式和内容:
1 | echo 1 > /sys/kernel/debug/tracing/tracing_on |
perf 性能分析工具
perf 是基于 Linux 内核提供的 tracepoint 性能事件 perf_events 来进行性能分析的工具。它可以用于分析 CPU 性能、内存性能、I/O 性能等方面的问题。
perf stat:用于统计性能事件的计数,例如 CPU 周期数、指令数、缓存命中率等。简单的屏幕输出,支持的指令可以用perf stat -h查看。perf stat -a sleep 10:统计全系统在 10 秒内的性能事件计数。假设有一个测试的可执行文件要分析,可以使用以下命令:
perf stat -e cycles,instructions,cache-references,cache-misses ./test_program- -a:显示所有 CPU 上的统计信息。
- -C:显示指定 CPU 上的统计信息。
- -e:指定要显示的事件。
- -i:禁止子任务继承父任务的性能计数器。
- -r:重复执行 n 次目标程序,并给出性能指标在 n 次执行中的变化范围。
- -p:指定要显示的进程的 ID。
- -t:指定要显示的线程的 ID。
perf record:用于记录性能事件的采样数据,可以生成性能分析报告。可以与-e选项指定要记录的事件类型。通过perf record -h查看指令参数比如针对 irq :
perf record -e "irq:irq_handler_exit,irq:irq_handler_entry" -a -- sleep 2- -a:分析整个系统的性能
- -A:以 append 的方式写输出文件
- -c:事件的采样周期
- -C:只采集指定 CPU 数据
- -e:选择性能事件,可以是硬件事件也可以是软件事件
- -f:以 OverWrite 的方式写输出文件
- -g:记录函数间的调用关系
- -o:指定输出文件,默认为 perf.data
- -p:指定一个进程的 ID 来采集特定进程的数据
- -t:指定一个线程的 ID 来采集特定线程的数据
perf report:针对perf record生成的采样数据进行分析和报告。通过perf report -h查看指令参数比如:
perf report- -c
:指定采样周期 - -C
:只显示指定 CPU 的信息 - -d
:只显示指定 dos 的符号 - -g:生成函数调用关系图,具体等同于 perf top 命令中的 -g
- -i:导入的数据文件的名称,默认为 perf.data
- -M:以指定汇编指令风格显示
- –sort:分类统计信息,如 PID、COMM、CPU 等
- -S:只考虑指定符号
- -U:只显示已解析的符号
- -v:显示每个符号的地址
- -c
perf annotate:用于查看特定函数或代码段的汇编代码,并采集显示每行代码的耗时,可以帮助我们找到代码、函数的执行瓶颈。通过perf annotate -h查看指令参数比如:
perf annotate -i perf.data- -C
:指定某个 CPU 事件 - -d:只解析指定文件中符号
- -i:指定输入文件
- -k:指定内核文件
- -s:指定符号定位
- -C

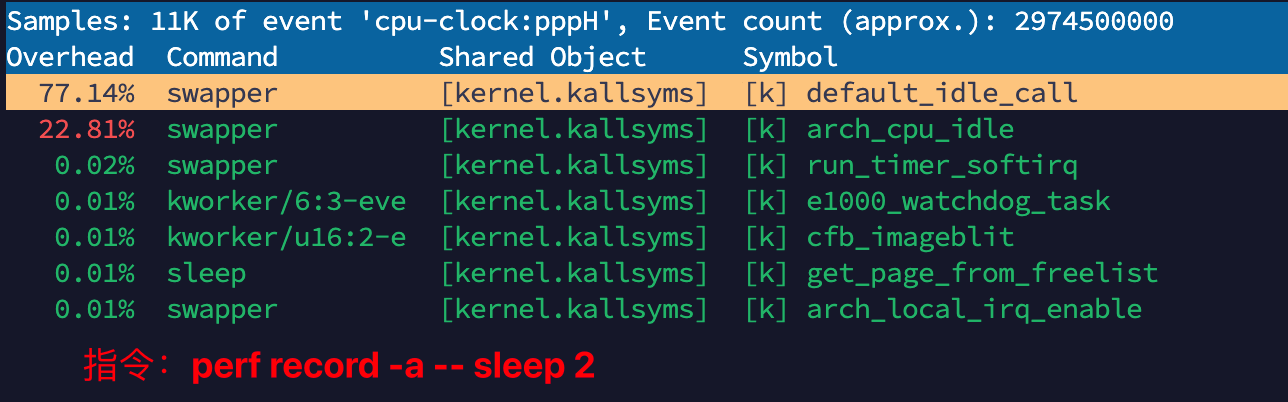
第一列:Children
这列表示当前函数或符号所占的执行时间占比。
例如,77.14% 表示该项在整个分析的执行时间中占用了 99.95%。
第三列:Command
这列显示了执行命令的名称。例如,swapper 是 Linux 内核中的一个常见进程,负责交换内存页。
第四列:Shared Object
这列显示符号所属的共享对象或库。
在这个例子中,[kernel.kallsysms] 表示这是内核的符号。
[k] 表示该符号或函数是在内核模式下执行的。
第五列:Symbol
这列列出了对应的符号或函数名称。例如:default_idle_call。
查看可用的性能事件
1 | perf -h |
生成火焰图
要生成火焰图必须有调用栈信息,所以需要在perf record时加上-g选项。
用perf record -g记录采样数据后,通过perf script > out.perf生成脚本文件,该脚本数据可以用于生成火焰图。
生成的
out.perf可以放到其他机器上生成火焰图,如果只有perf.data的话,需要把/proc/kallsyms文件也一起复制过去,因为生成火焰图需要解析符号表。
1 | perf record -g ./test |
然后使用FlameGraph工具生成火焰图。
1 | git clone https://github.com/brendangregg/FlameGraph.git |
生成火焰图:
1 | ./stackcollapse-perf.pl ../out.perf > out.folded |
将生成的flamegraph.svg文件用浏览器打开即可看到火焰图。
实战
代码
写一个简单的测试程序 test.c:
1 |
|
编译并运行(运行的时候加上 perf record):
1 | gcc -o test test.c |
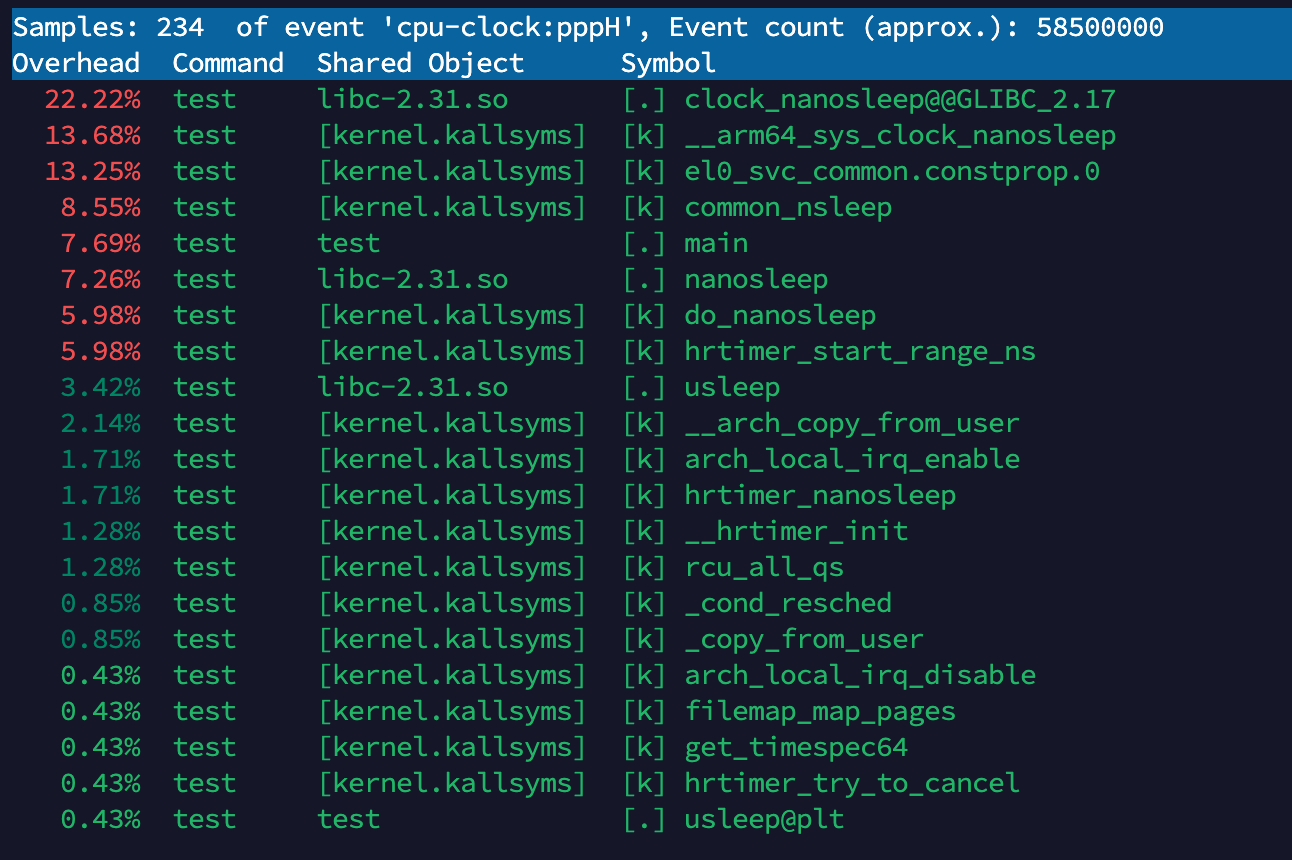
22.22% test libc-2.31.so clock_nanosleep@GLIBC_2.17:
这表示 test 程序在执行时,clock_nanosleep 函数占用了 22.22% 的 CPU 时间。
clock_nanosleep 来自 libc-2.31.so 库,表示程序在执行睡眠操作(或者等待)时占用了大量 CPU 时间。
13.68% test [kernel.kallsysms] __arm64_sys_clock_nanosleep:
这个符号表示内核调用 __arm64_sys_clock_nanosleep,也就是说内核在处理 clock_nanosleep 系统调用时占用了 13.68% 的 CPU 时间。
__arm64_sys_clock_nanosleep 是 ARM64 平台下的系统调用处理函数。
13.25% test [kernel.kallsysms] el0_svc_common.constprop.0:
该符号与内核中系统调用的处理有关,尤其是与特定的服务调用(SVC)相关。
SVC(Supervisor Call) 是一种特权指令,用于从用户模式切换到内核模式。
8.55% test [kernel.kallsysms] common_nsleep:
这个符号表示内核中的 common_nsleep,与常见的睡眠操作有关。它占用了 8.55% 的 CPU 时间。
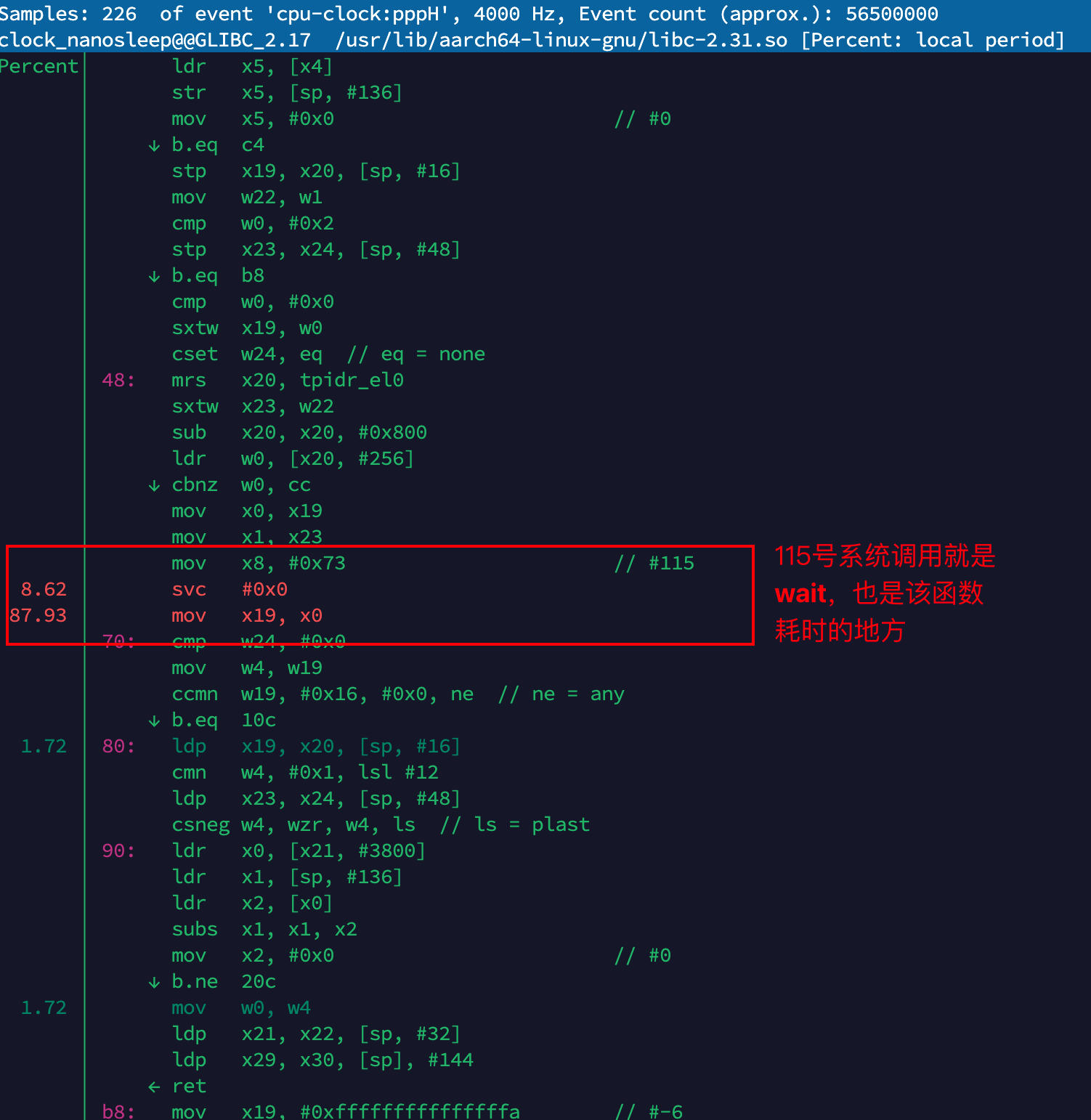
耗时排查
下面针对这个测试程序通过annotate查看具体的汇编代码及耗时百分比:
1 | perf record -g ./test |
火焰图
下面针对这个测试程序生成火焰图:
1 | perf record -g ./test # -g: 记录完整的调用栈,有完整的调用栈才能生成火焰图 |
生成火焰图的效果图:
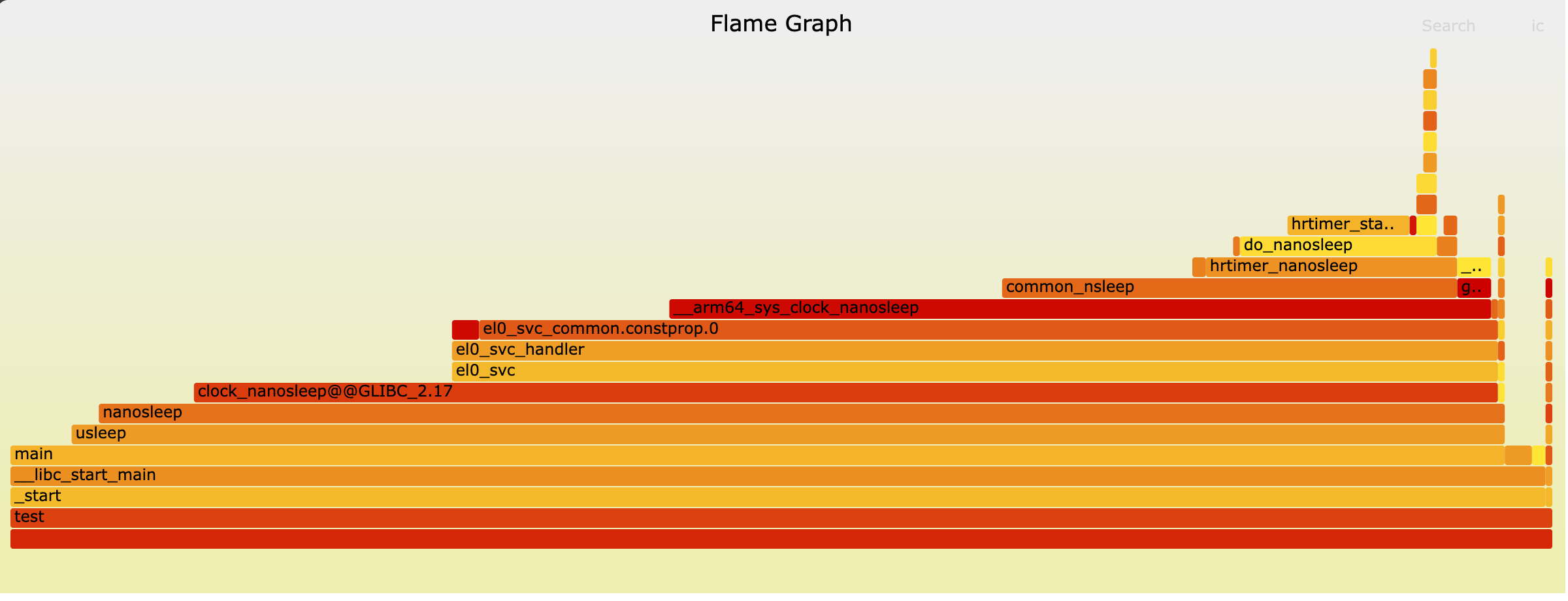
这个火焰图主要显示了程序在执行 usleep()
导致的系统调用 nanosleep()
时花费了大量时间。您提供的代码正是导致此性能特征的原因。
- Y轴(垂直方向): 表示函数调用栈的深度。底部的函数是调用者(父函数),其上方的函数是被调用者(子函数)。
- X轴(水平方向): 表示该函数在性能分析采样期间占用的 CPU 时间比例,宽度越宽,表示占用 CPU 时间越长。X轴上的顺序没有特定的时间含义,仅用于最大化地合并相同调用栈的矩形块。
- 颜色: 通常没有特定含义,仅用于区分不同的函数或表示新旧版本对比等。
结合代码中有一个循环,每次循环都会调用
usleep(1000)(睡眠 1 毫秒)。
1 | for (int i = 0; i < times_s * 1000; ++i) { |
这个火焰图显示:
- 最底层的 test(您的程序二进制文件,或 main 函数)是程序的起点。
- main 函数调用了 libc_start_main,然后调用 usleep。
- usleep 最终导致了 nanosleep 或类似的系统调用,例如 hrtimer_nanosleep 和 do_nanosleep,这些调用在图中形成了最宽的“火焰尖”。
结论: - 图中最宽的区域是与 nanosleep 相关的系统调用栈。这表明您的程序大部分时间都花在了“睡眠”(等待)状态,而不是在执行计算任务。火焰图有效地指出了性能瓶颈在于频繁且耗时的睡眠操作。
tmp
ftrace主要用于跟踪时延和行为
perf的原理是这样的:每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。 很明显可以看出,这是一种采样的模式,我们预期,运行时间越多的函数,被时钟中断击中的机会越大,从而推测,那个函数(或者pid等)的CPU占用率就越高。(所以不是完整样本,具有概率性) 参考:https://mysummary.readthedocs.io/zh/latest/软件构架设计/在Linux下做性能分析.html#id1
sudo perf record -e 'cycles' -- myapplication arg1 arg2 sudo perf report
另外,我们要清楚,现代CPU基本上已经不用忙等的方式进入等待了,所以,如果CPU在idle(就是没有任务调度,这种情况只要你的CPU占用率不是100%,必然要发生的),击中任务也会停止,所以,在Idle上是没有点的(你看到Idle函数本身的点并非CPU Idle的点,而是准备进入Idle前后花的时间),所以,perf的统计不能用来让你分析CPU占用率的。ftrace和top等工具才能看CPU占用率,perf是不行的。
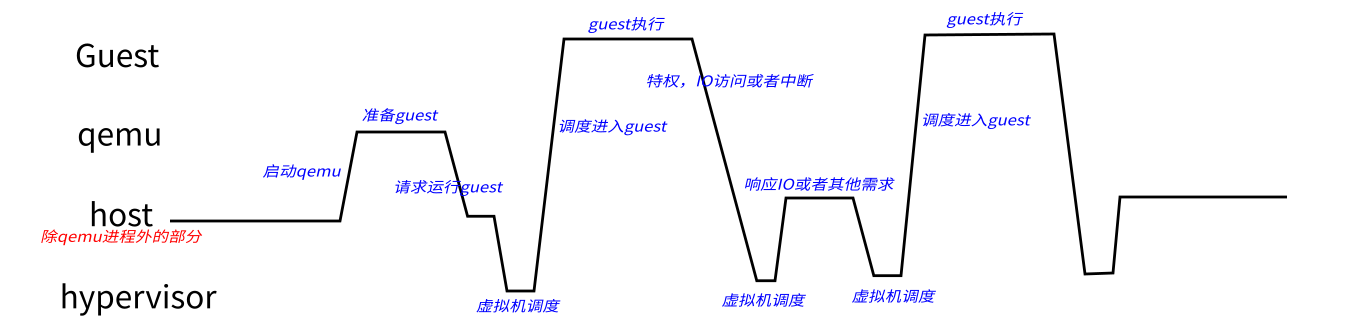
qemu guest host hypervisor的陷入陷出流程
从这个图上我们可以看到,除了掌握更多的资源(IO资源),Host的地位和Guest地位几乎是对等的。这造成一个很有趣的现象:如果我们在host上用top来看进程的CPU的占用率,Guest占掉的CPU是算在qemu头上的,因为从时间上来说,host确实看到CPU进入qemu后,就没有出来了。但如果用perf top来看,你却看不见qemu占用CPU,因为PMU的中断打进来后,如果调度到Guest中,Host是看不到这个打的点的。所以perf top的报告是qemu占用并不高。
反过来,如果我们在Guest看,top看不见Host抢去的CPU,Guest从这个角度是看不到Host或者其他Guest抢去的CPU的时间的。Perf top同样看不到,因为Guest的中断基本上都是Host种进去的,它只能统计它自己看到的点。
kvm_entry是进入guet,kvm_exit是离开guest进入host/kvm