
DSB SY:数据屏障指令,多核数据同步问题,主要解决内存数据还未写入,就被乱序的指令读取的问题。 - dsb(sy) 会等待其他核的广播应答后,才算完成
ISB:指令屏障,清空 ISB 后面的指令,并把还没执行的指令丢掉,重新取值(比如让CPU重新读取寄存器状态)。ISB 不会管TLB缓存是否一致,只管指令状态,所以只用 ISB 会存在缓存一致性问题。 - ISB不会等广播应答
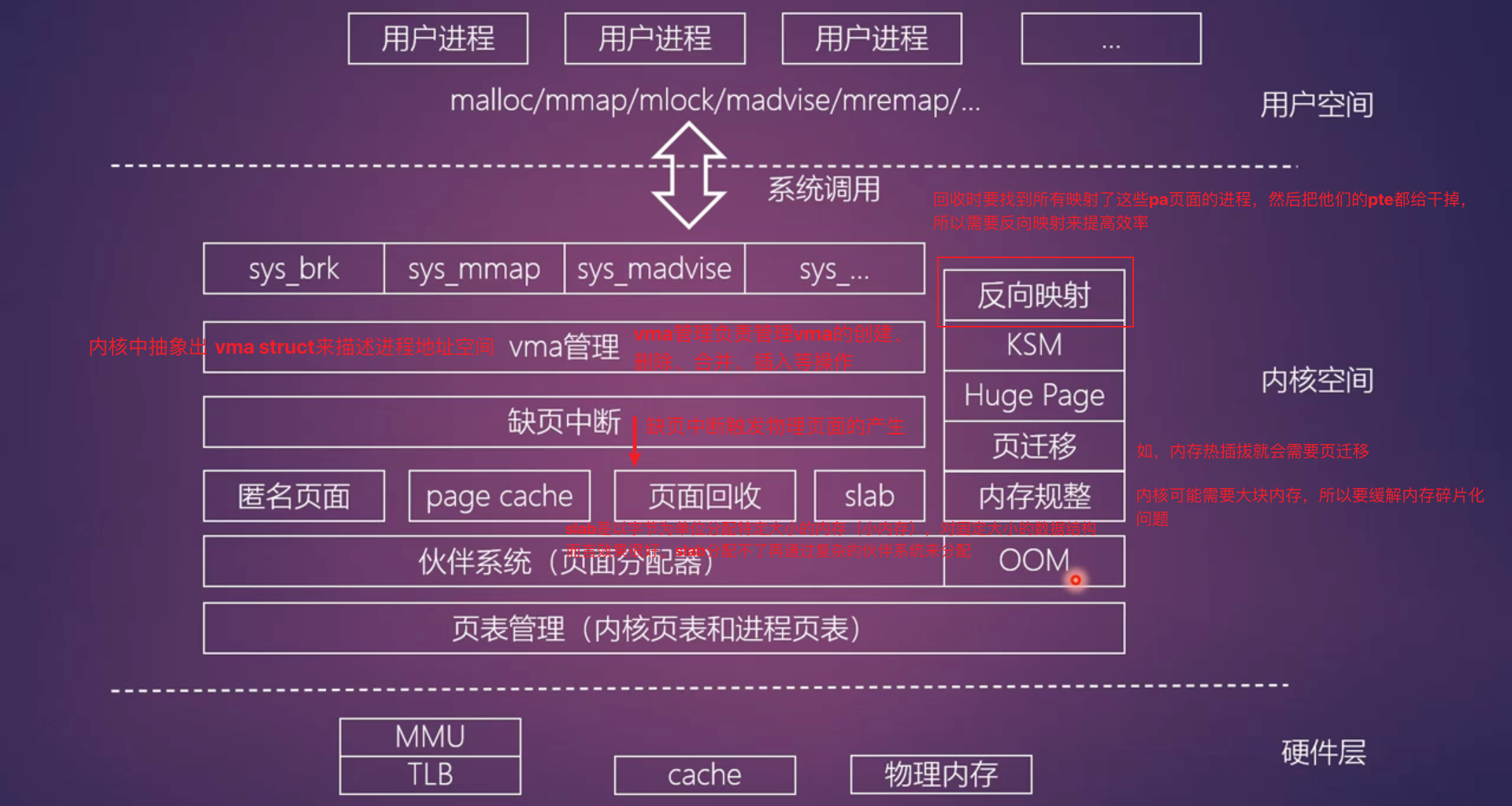
内存管理篇
多进程内存分配
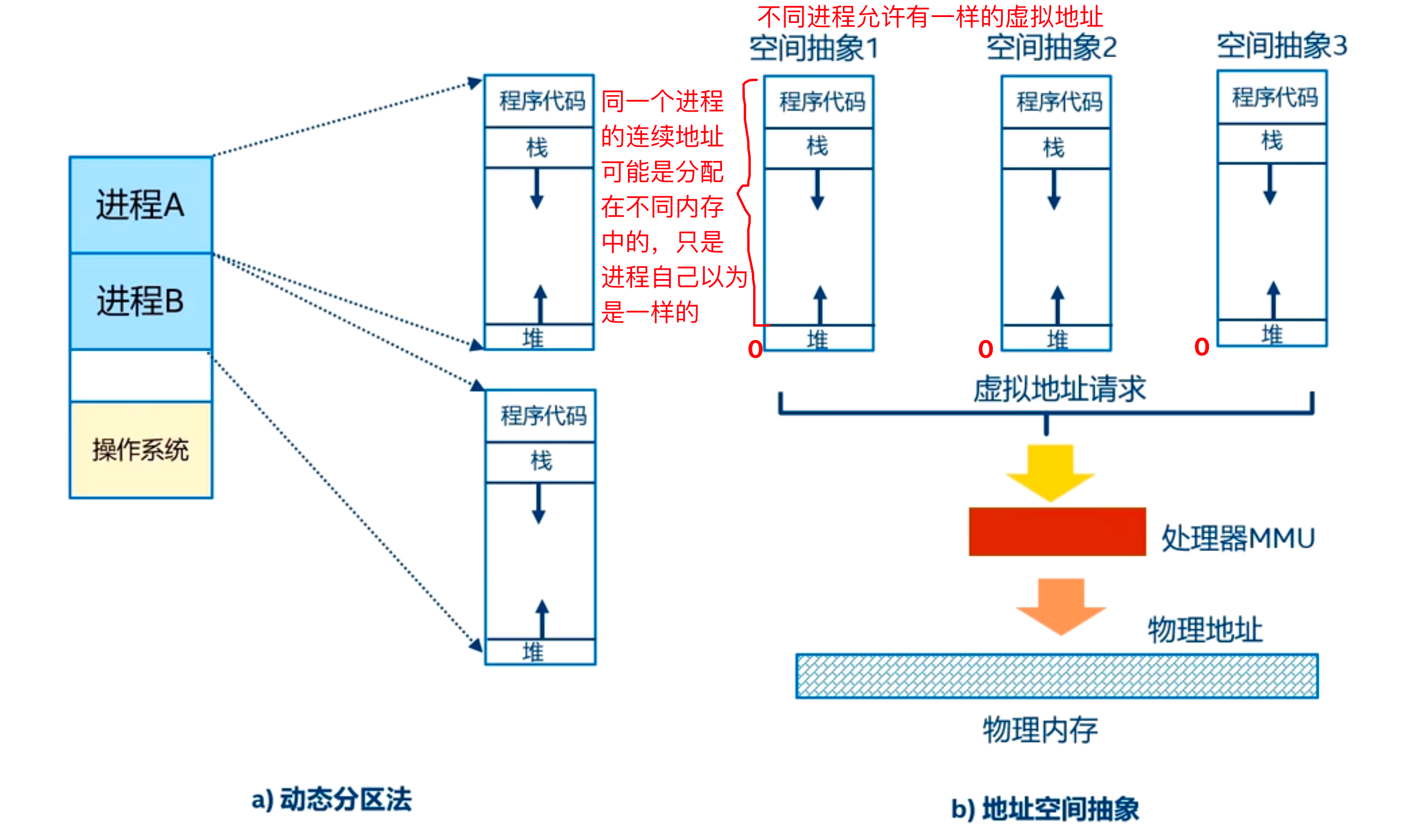
- 虚拟存储器:操作系统为每个进程提供的抽象内存空间。它让每个进程都认为自己拥有连续、独占的大块内存(通常从0到最大地址),实际上这些数据可能分散在物理内存的不同位置,甚至暂时存储在磁盘上。
- 虚拟地址空间:每个进程独立的地址视图。两个进程可以使用相同的虚拟地址,但它们映射到不同的物理内存区域。
- 物理存储器:计算机实际的硬件内存(RAM)。这是数据真正存储的地方,由物理地址直接访问。
- 页帧:物理内存被划分的固定大小块。例如4KB、2MB或1MB。每个页帧有一个唯一的物理页帧号(PFN)。
- 虚拟页帧号(VPN):由虚拟地址中的高 N
位组成,用于页表翻译时的查表。虚拟地址 = VPN +
偏移量(Offset)。例如在4KB分页、48位虚拟地址的系统中:
- 高36位:VPN
- 低12位:偏移量(0-4095)
- 物理页帧号(PFN):物理内存中页帧的编号。物理地址 = PFN + 偏移量。VPN通过页表映射到PFN。
- 页表 PT:存储虚拟地址到物理地址映射关系的数据结构。每个进程都有自己的页表。页表本质是一个数组,索引是VPN,元素是页表项。
- 页表项 PTE:页表中的每个条目,包含:
- PFN:对应的物理页帧号
- 有效位:该页是否在物理内存中
- 读/写/执行权限位:控制访问权限
- 脏位:页是否被修改过
- 访问位:页是否被访问过
- 其他控制位:如缓存策略、用户/内核模式等
他们之间的结构关系为:
1 | 页表(PT) |
查找过程 1. VPN作为索引:用虚拟页帧号(VPN)直接访问页表数组
从PTE中提取PFN:页表项中存储了物理页帧号
组合成物理地址:PFN + 偏移量
查找过程可以概括为以下的过程:
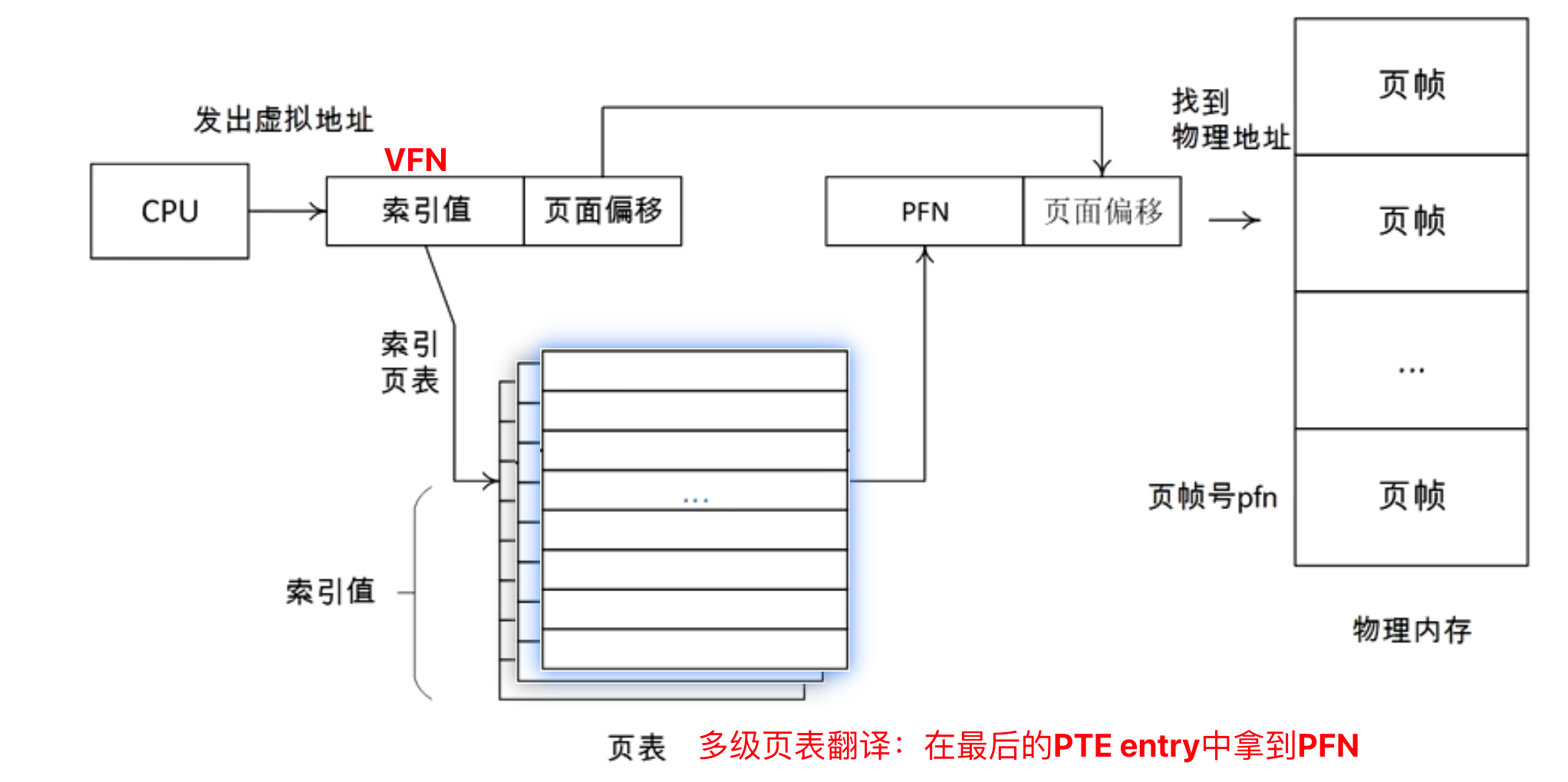
虚拟地址翻译流程
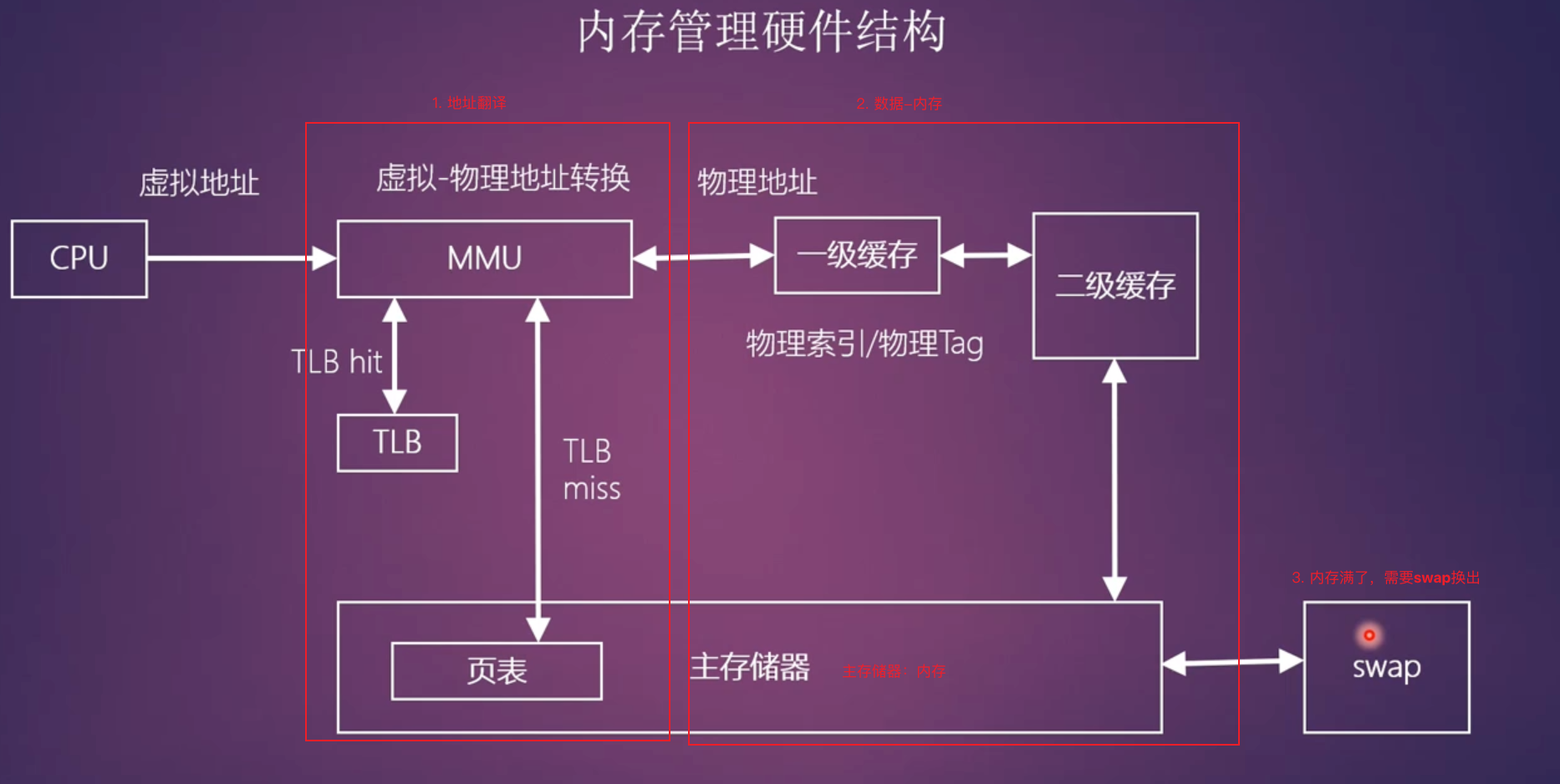
虚拟地址到物理地址的映射由 MMU 来实现,是纯硬件实现的,它的地址翻译流程如下所示,这里只画出了二级页表的情况,实际上现代系统普遍使用多级页表,ARM64 架构通常支持三级或四级页表(取决于虚拟地址位数和配置):
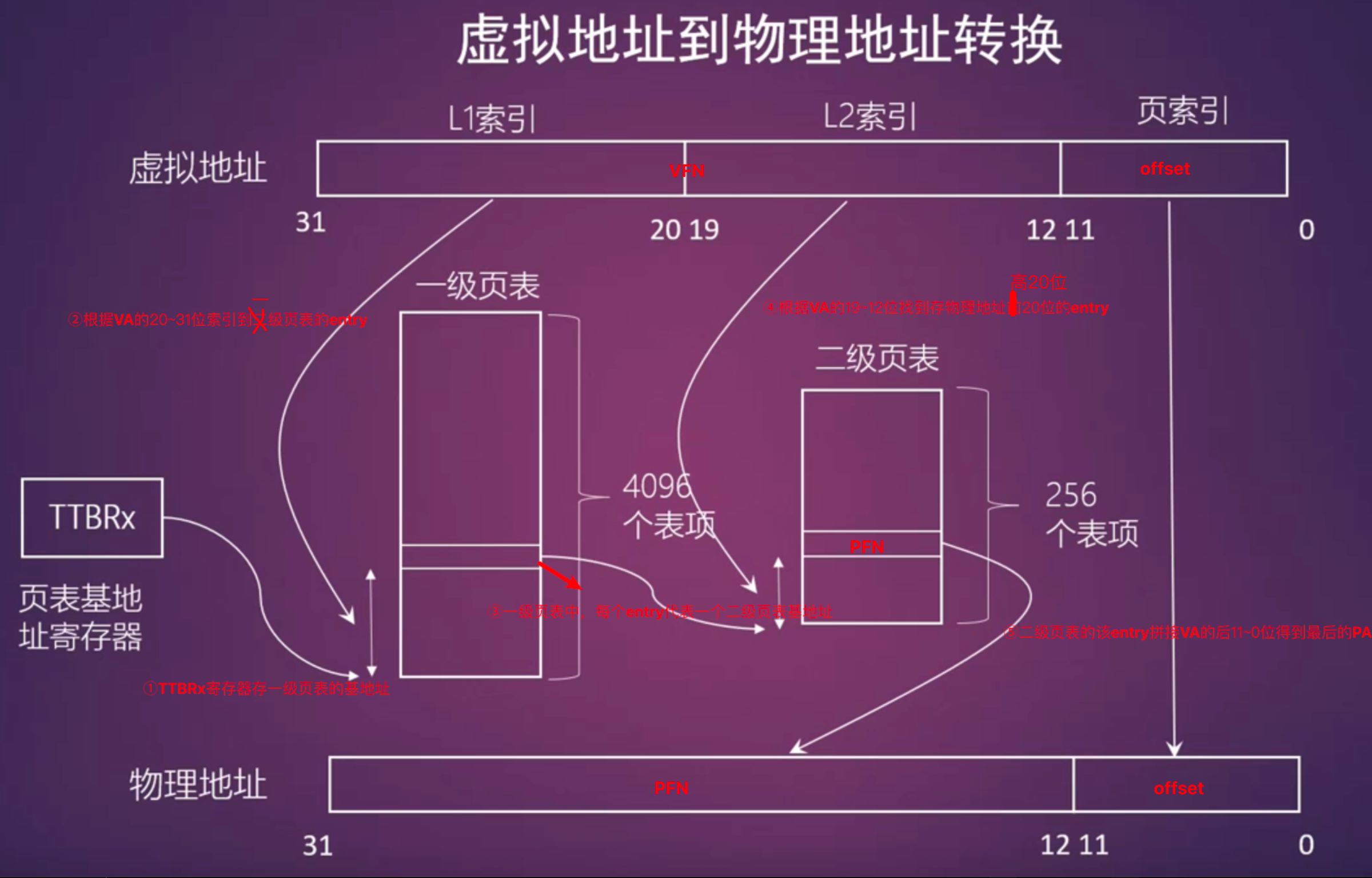
现代 Linux 内核在 ARM64 上默认使用 四级页表(PGD → PUD → PMD → PTE)。
假设目前有一个页,它的64bit虚拟地址是[VFN=0xffff018140e09]+[offset=0x000]。由于内存是字节寻址的,因此我们可以以字节的形式进行访问,所以这个例子是:
1 | 访问这个页的第一个字节,地址是[0xffff018140e09]000 |
这一整个PTE页所有 entry 的高 36 位都是一样的。
虽然地址翻译由 MMU 硬件完成,但页表由操作系统软件管理。需要通过软件维护页表,比如创建页表、更新页表项、通过设置页表项中的权限位来控制访问权限(如读写权限、用户态/内核态权限等).
用户/内核空间页面管理
linux 系统把地址空间分为用户空间和内核空间两部分,用户空间的地址由用户态程序使用,内核空间的地址由操作系统内核使用。
- 较低的地址范围用于用户空间(0~3GB)
- 较高的地址范围用于内核空间(3GB~4GB)
flowchart LR
A[VMA查找触发场景] --> B[缺页中断处理]
A --> C[内存分配与映射]
A --> D[内存保护与权限检查]
A --> E[进程信息查询与调试]
B --> B1[查找发生缺页的虚拟地址
所属的VMA]
B1 --> B2{VMA是否存在?}
B2 -- 是 --> B3[权限检查]
B2 -- 否 --> B4[发送SIGSEGV信号
终止进程]
B3 --> B5[分配物理页面
建立映射]
C --> C1[malloc/mmap]
C1 --> C2[查找空闲区域
或检查映射冲突]
C2 --> C3[创建或扩展VMA]
D --> D1[访问非法地址
或权限违规]
D1 --> D2[快速定位VMA
进行权限判断]
E --> E1[读取 /proc/pid/maps]
E1 --> E2[遍历进程所有VMA
格式化输出]
匿名页面(通常是进程的私有数据)、page cache、slab都有自己的链表结构来组织页面
对于页面回收而言,内核比较喜欢回收干净的page cache
ksm是服务虚机的,系统中创建很多一样的虚机,会产生很多相同的匿名页面,所以ksm的作用就是把他们合并起来,减少内存占用
大页(Huge Page)
我们常用的页大小是4KB,但在某些场景下,使用更大的页(如2MB或1GB)可以显著提高性能,减少TLB miss的次数。
1 | 48位虚拟地址 |
对比说明: - offset 位数 = log2(页大小) - PFN 位数 = 48 - offset 位数 - 页越大,offset 占用位数越多,PFN 位数越少,TLB 条目覆盖范围越大
大页:mmu访问页表的消耗是很严重的,以二级页表为例,一次tlb miss就会导致两次内存访存;所以huge page的最大的好处是可以减少 tlb miss 次数,比如,你现在需要分配2mb内存,如果使用4k的页面,需要tlb miss 512次
flowchart LR
subgraph A["使用4KB页 (2MB区域 = 512页 PTE)"]
direction LR
A1["需要512个虚拟页
(VPN 0~511)"]
A2["需要512个PTE
(页表项)"]
A3["需要512个TLB条目
才能完全映射"]
A1 --> A2 --> A3
end
subgraph B["使用2MB大页 (2MB区域 = 1页 PMD)"]
direction LR
B1["仅需1个虚拟页
(VPN 0)"]
B2["仅需1 个PTE"]
B3["仅需1个TLB条目
即可完全映射"]
B1 --> B2 --> B3
end
A3 --> C["结果:TLB空间压力大
转换开销大、易缺失"]
B3 --> D["结果:TLB空间压力极小
转换快、命中率高"]
大页虽然对大内存很友好,但是分配小内存是就会有浪费的问题。
如果在开启了2MB大页的情况下,你的应用只需要4KB的内存,整个映射和查找过程操作系统必须在物理内存中找到一段连续的2MB物理内存块。这与普通4KB页不同,普通页只需4KB连续,而大页强制要求2MB连续。
结果:一个页表项(PDE)直接映射了2MB的物理空间。虽然你只用了4KB,但在硬件看来,这2MB空间现在都属于你。
地址计算:命中后,直接用物理地址高位(PPN)拼接虚拟地址的低位(Offset,即页内偏移),得到最终物理地址。对于2MB页,偏移量是21位。
现代操作系统的解决方案(透明大页 THP):
Linux的透明大页(THP)机制很好地解决了你的疑虑。它的行为是动态的: - 进程申请内存,内核默认按4KB页分配。 - 内核后台线程扫描,发现进程占用了大量连续的4KB页。 - 内核尝试将这些连续的4KB页合并成一个2MB大页。 - 如果进程后续只访问其中4KB,或者修改局部权限,内核甚至可以将大页拆分回4KB页。
结论: 如果是静态开启大页(如HugeTLB),映射和查找都按2MB粒度进行,TLB中只有一条记录,效率极高但内存浪费严重;如果是透明大页,内核会动态调整,尽量让你“既享受大页的速度,又不失小页的灵活”。
2MB大页的页表结构:
| 逻辑名称 | Linux内核常用名 | 索引级别 | 区间 |
|---|---|---|---|
| Page Global Directory | PGD | 一级 | [47-39] |
| Page Upper Directory | PUD | 二级 | [38-30] |
| Page Middle Directory | PMD | 三级(关键转折点) | [29-21] |
| Page Table Entry | PTE | 四级(2MB大页时无四级) | [20-12] |
第 4 级 PTE 页表每个 entry 能映射的内存空间大小是由 offset 位数决定的,比如当前 offset 有 12 位,那么 PTE 页表项就能映射 2^12 = 4KB 的内存空间。
那么同理,每个 PMD 页表项能映射的内存空间大小就是 2^(12+9) = 2^21 = 2MB 的内存空间了。
从上面的表格分段情况也可以看出,4 级页表中,每级页表用 9 bit 来索引,所以每级页表有 512 个 entry(2^9 = 512),每个 entry 可以映射 4KB 的页,所以每级页表可以映射 512 * 4KB = 2MB 的内存空间,这也是为什么 PMD 级别的一页可以直接映射一个 2MB 大页的原因。
以一个2MB大页为例,48 bit 地址长度为例,虚拟地址的页表翻译过程如下图所示,在:
flowchart TD
VA["VA 48bit"]
subgraph SPLIT
direction LR
L0["47-39 L0 idx"]
L1["38-30 L1 idx"]
L2["29-21 L2 idx"]
L3["20-12 L3 idx"]
OFF["11-0 Offset"]
end
VA --> SPLIT
%% L0
L0 --> TTBR["TTBR base"]
TTBR --> D0["L0 desc TABLE"]
%% L1
D0 --> L1T["L1 table PGD"]
L1T --> D1["L1 desc"]
D1 -->|BLOCK 1GB| PA1["PA = OA(47-30) + VA(29-0)"]
D1 -->|TABLE| L2T["L2 table PUD"]
%% L2
L2T --> D2["L2 desc"]
D2 -->|BLOCK 2MB| PA2["PA = OA(47-21) + VA(20-0)"]
D2 -->|TABLE| L3T["L3 table PMD"]
%% L3
L3T --> D3["L3 desc PAGE"]
D3 --> PA3["PA = OA(47-12) + VA(11-0)"]
可以看出,在2MB大页模式下,PMD级别的页表项直接指向一个2MB的物理内存块,而不需要再访问PTE级别的页表了,这样就减少了一次内存访问,提高了地址翻译的效率。
在这种页表翻译的情况下,拿到实际 PA 物理地址后,也会通过地址总线访问内存
flowchart TD
%% CPU + MMU
subgraph CPU["CPU + MMU"]
VA["VA 0x...1234"]
MMU["MMU translate"]
PA["PA block_base + offset"]
VA --> MMU
MMU --> PA
end
%% Bus
PA --> BUS["AXI Bus"]
%% Memory
subgraph MEM["Physical Memory (2MB Block)"]
direction TB
B0["offset 0x000000"]
B1["offset 0x001000"]
B2["offset 0x001234 target"]
B3["offset 0x1FFFFF"]
end
BUS --> MEM
%% highlight
style B2 fill:#ffcccc,stroke:#333,stroke-width:2px
访问 2mb 大页其中一个 4k 内存时,tlb的地址命中过程如下:
flowchart TD
A["VA 0x234567"] --> B["MMU split"]
B --> C["VA = base 0x200000 + offset 0x034567"]
C --> D["TLB lookup"]
subgraph TLB["TLB entries (连续地址范围)"]
direction LR
D1["2MB entry\nbase 0x200000\nsize 2MB\nrange: 0x200000-0x3FFFFF"]
D2["4KB entry\nbase 0x400000\nsize 4KB\nrange: 0x400000-0x400FFF"]
D3["EntryN ..."]
end
D --> TLB
TLB --> E{"VA 在哪个条目范围内?"}
E -- "命中 2MB 块
VA = 0x200000(base) + 0x034567(offset)
范围检查: 0x200000 ≤ VA < 0x400000" --> F["获取 OA base"]
E -- "未命中" --> G["页表遍历 page table walk"]
F --> H["offset = VA - base = 0x234567 - 0x200000 = 0x034567"]
H --> I["PA = OA base + offset"]