
1. vim
.:小数点,重复上一次的命令
vim 中进行查找
1)基本查找命令
查找下一个匹配项:
1 | /<搜索内容> |
- 按下 / 键,输入要查找的内容,然后按下回车键 Enter。
- 例如:
/hello表示查找 hello
2)跳转到另一个查找结果
/hello查找后,要先按 enter 键,然后按 n
键才能跳转到下一个匹配项。
- 跳转到下一个匹配项:按
n键 - 跳转到上一个匹配项:按
N键
vim 中复制粘贴
复制:
yy: 复制当前行nyy: 复制从当前行开始的 n 行(例如:3yy复制当前行及其下两行,共三行)
粘贴:
p: 在光标后粘贴
光标移动
NG: 跳转到第 N 行:n: 跳转到第 N 行(好用!)gg: 跳转到第一行, 相当于1GG: 跳转到最后一行w: 光标跳到下一个单词的开头e: 光标跳到当前单词的结尾$: 跳转到这一行的末尾%: 跳转到匹配的括号处(大括号、中括号)*: 高亮显示所有与当前光标所在单词相同的单词处- 按
n跳转到下一个匹配处 - 按
N跳转到上一个匹配处
- 按
组合命令:
example:
0y$: 复制从行首到行尾的内容0: 行首y: 复制+y:复制选中的内容到系统剪贴板。(需要安装 xclip,通过:version查看当前是否支持与系统剪贴板交互,-clipboard为不支持)$: 行尾
其他高级组合用法符号说明:
viw:选择当前单词(包括单词的前后空格)0: 行首^: 到本行第一个非空字符$: 行尾g: 到本行最后一个非空字符fa: 到下一个匹配的字符 a 处(可以改变 a 为其他字符)t,: 到逗号前的第一个字符(逗号可以改变为其他字符)
配置vim显示行号
1 | 打开vimrc配置文件 |
在vimrc配置文件中添加如下内容:
1 | set number "行号显示 |
vim 双屏
方法一:vsp
vim
查看一个文件后,用:vsp来跟另一个文件进行比较(双屏)
1 | vim ./file1.c |
如果要打开另一个文件:
1 | :e ./file3.c |
然后如果要切到第二个屏进行查找的话,可以用快捷键CTRL+ww或者CTRL+h/j/k/l通过方向键切过去
方法二:-O
加上-O参数直接多屏打开多个文件,通过垂直屏幕的方式。
1 | vim -O file1.c file2.c |
vim 中显示当前文件的 路径&&文件名
在底部输入:f然后 Enter
vim 中多个文件选择和切换
1 | :buffers |
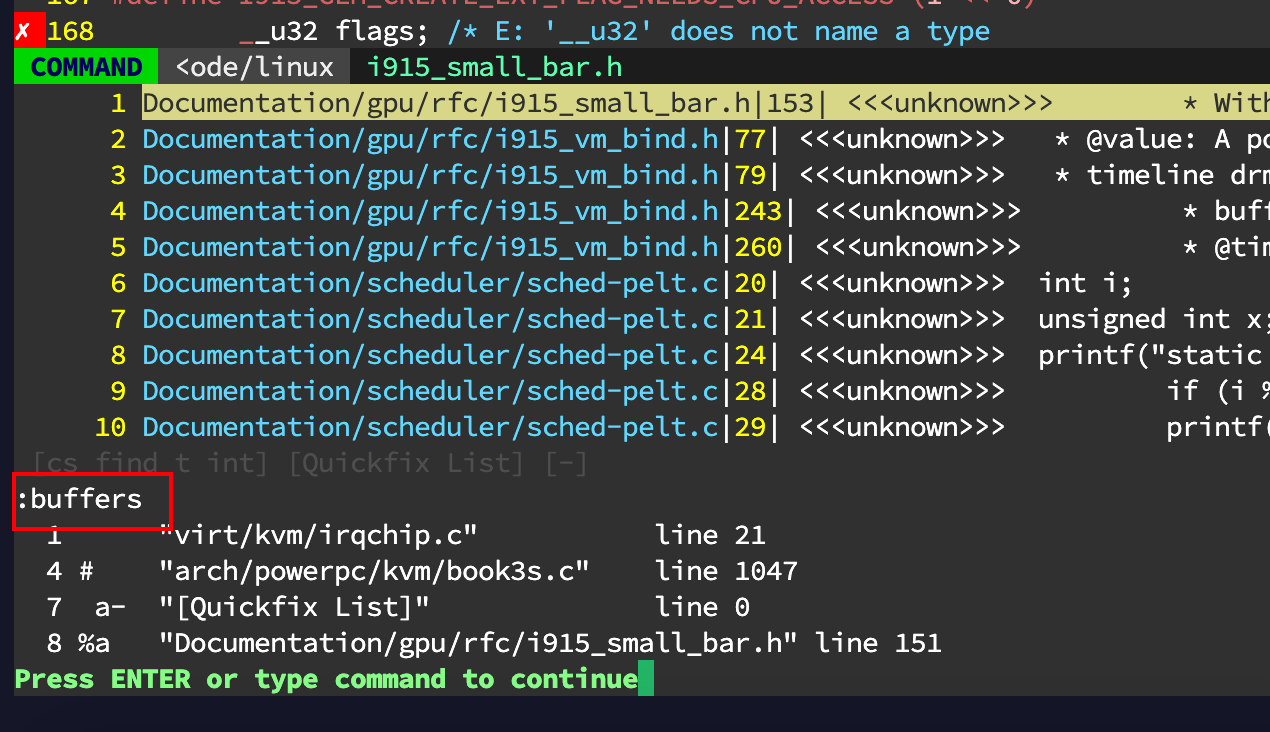
然后找到要跳转的文件的编号,比如上图中的irqchip.c的编号是1,然后输入:
1 | :buffer 1 |
vim 块操作
多行注释:
ctrl+v进入可视化模式- 按方向键向下多选同一光标下的多行
- 选完按
shift+i - 然后输入想输入的符号(如注释)
- 输完按
esc退出编辑模式后就会发现选中的块都加上了注释
如果想实现比如,把//删除然后替换成“,需要: -
ctrl+v - l 向右选中“//” - j
选中多行 - 按 c 删除,并输入 “ 添加
“ 字符 - 最后按 esc键退出编辑模式
2. terminal 操作
find
查找并忽略没有权限的文件的报错信息:
1 | find / -name "文件名.c" 2>/dev/null |
查找内核的路径
uname -a: 显示当前内核信息
ls -l /usr/src: 找到 uname -r 显示的版本的内核路径
查看bios版本
sudo dmidecode -t bios
查看操作系统版本
cat /etc/os-release
查看磁盘哪个占用最高
1 | df -h |
1 | 18G /home |
假设逐层检查发现是 /var/crash
占用最高,如果确认占用最高的目录删除后没有影响,那么就删除该目录:
1 | rm -rf /var/crash/* |
查看 CPU 使用率
通常用top就能查看,但是如果要指定查看某个CPU的使用率可以用mpstat -P 1 1,这个还可以查看中断率
设置环境变量
用 export 命令设置环境变量,例如:
配置路径:
1 | export PATH=$PATH:/usr/local/bin |
配置变量:
1 | export $VAR=value |
开关内核打印
有时候我们在应用层调试程序的时候想暂时屏蔽掉内核的无用打印,可以在 host 用以下方法暂时关闭,这样开启 guest 虚机的时候就不会将内核信息打印到主机中,影响性能:
1 | echo 0 > /proc/sys/kernel/printk |
打开内核打印:
1 | echo 7 > /proc/sys/kernel/printk |
内核编译选项
查看已经启动的内核是否包含哪个编译项
内核的编译选项一般存在/boot/config-$(uname -r)中,所以可以结合grep查看当前内核有没有编进去你想找的编译选项
1 | 查看当前包含的所有编译选项 |
查看编好的 rpm 包是否包含某个编译选项
如果是编了 rpm 包,还没有 rpm 添加进服务器内核,且没有更新内核的话:
1 | rpm2cpio kernel-xxx.rpm | cpio -idmv # 这样会把内核解压到当前目录下,生成一个`boot`和`lib`目录 |
对于已经rpm -qa安装的内核包,可以用以下命令查看内核编译选项:
1 | rpm -q --configfiles kernel-<version>.rpm |
linux rpm 包添加 tracing
如果内核没有编译 tracing,可以重新编译内核,添加 tracing 编译选项:
1 | CONFIG_FTRACE=y |
修改 linux-root 密码
1 | sudo passwd root |
设置维持 ssh 连接不断连
1 | sudo vim /etc/ssh/sshd_config |
然后在文件中写入如下内容: 1
2Host *
ServerAliveInterval 60
最后,记得重启sshd服务:service sshd restart
scp,cp
服务器与服务器之间进行文件传输用scp
scp user1@ip1:/home/user1/file1.txt user2@ip2:/home/user2/file2.txt
单个服务器内进行文件复制粘贴用cp
cp file1.txt file2.txt
cp -r /home/dir1 /home/dir2
在源目录下有子目录时,用-r参数,表示递归复制
ll 文件字节数
1 | akira@akira:~/linux-code$ ll tags |
1005478272单位是字节,以3位为间隔,可以展开成1,005,478,272
- 1005478.272 KB
- 1005.478272 MB
- 1.005478272 GB
修改默认内核选项
方法一(推荐)
这个方法不会把其他内核的 cmdline 刷掉,配完就可以直接重启了
1 | grubby --default-kernel #查看默认启动内核 |
方法二
先查看你要改为默认选项的内核的编号
1 | awk -F\' '/menuentry / { print i++ " : " $2 }' /boot/efi/EFI/openEuler/grub.cfg |
然后修改grub配置文件,将GRUB_DEFAULT的值改为目标内核编号:
1 | cp /etc/default/grub /etc/default/grub.bak |
3. gdb 调试
常用指令
1 | gdb-multiarch --tui ./build/xxx.elf |
1 | layout regs # 查看寄存器 |
查看某个地址处内存的值:
按当前寄存器值查看
看 x1 指向的同一块目的地址x/4xg 0x200000
查看变量值
- 查看变量值
你可以在调试过程中查看变量的值。例如,要查看 index 的值:
1 | (gdb) print index |
查看 data 数组的某个元素:
1 | (gdb) print data[0] |
print / p
1 | p var # 打印变量值 |
print string 指针
1 | p s |
print 数组
1 | p arr # 打印数组指针 |
设置断点
函数断点
1 | break main # 在 main 函数处断点 |
行号断点
1 | break main.cpp:25 # 在 main.cpp 第25行设置断点 |
条件断点
1 | break main.cpp:30 if i==5 # 仅当 i==5 时停下 |
运行与继续执行
1 | run # 从头开始运行 |
单步调试
step / s:进入函数内部执行
1 | step |
next / n:执行下一行,但不进入函数内部
1 | next |
你已经在 print_el 里了,那就直接跳出去:
1 | (gdb) finish |
跳到下一个断点:
1 | # 设置多个断点后,连续执行到下一个断点 |
stepi / si:按 CPU 指令单步执行
1 | stepi |
nexti / ni:按指令单步,但不进入函数
1 | nexti |
调试线程
如果你的程序使用了多线程,gdb 会处理每个线程。你可以使用以下命令查看线程:
1 | (gdb) info threads |
这个命令会列出所有线程及其状态。你可以使用以下命令切换到某个特定线程:
1 | (gdb) thread <thread_number> |
例如,如果你想切换到线程 2:
1 | (gdb) thread 2 |
普通可执行文件调试
1. 添加编译参数
首先确保编译可执行文件的Makefile中添加了-g参数:
1 | gcc -g ...... |
2. 启动调试器
在编译完成后,启动 gdb 调试器:
1 | gdb ./my_program |
这将启动 gdb 并加载你的程序 my_program
3. 设置断点
你可以在你想要的地方设置断点。例如,要在 access_data_array 函数的开头设置断点,可以使用以下命令:
1 | (gdb) break access_data_array |
或者,你也可以在特定的行号处设置断点。例如,设置在第 18 行 处:
1 | (gdb) break 18 |
4. 运行程序
1 | (gdb) run |
4. qemu 使用
将虚机 log 存到文件中
1 | 用 tee 指令可以实时把 log 输出到终端的同时也写入到文件中 |
qemu 指令
qemu 制作共享镜像
1 | qemu-nbd -f qcow2 -c /dev/nbd0 /path/to/image.qcow2 |
qemu 主线编译运行
克隆QEMU工程
克隆工程时必须加入g--recurse-submodules把子工程一并克隆下来
1 | git clone --recurse-submodules https://github.com/qemu/qemu.git |
注意:克隆工程时一定要加上--recurse-submodules,否则很容易出现版本问题
QEMU编译
编译arm64架构下的qemu虚拟机:
1 | mkdir build |
编译完确认没报错后,需要打包生成的qemu-system-aarch64,然后由于选择的是动态编译,所以需要把所有的动态库打包进去:
1 | mkdir qemu_build |
测试验证
将编译的qemu放到开发板中进行测试验证
1 | scp qemu_build.tar.gz <user>@<server>:</path/> |
启动虚机:
1 | ./qemu_build/qemu_build/qemu-system-aarch64 -machine virt,gic-version=3 \ |
如果编译中出现库找不到的问题,可能是因为编译机跟开发机环境不一样,可以尝试下面的方法:
1 | patchelf --set-rpath '$ORIGIN/libs' ./qemu_build/qemu-system-aarch64 |
virsh 指令
1 | 安装相关依赖和启动服务 |
查看用qemu起的虚机 pid
ps -ef | grep qemu
ps aux | grep qemu
5. Linux 中对工程代码的跳转、函数查找
vim 中函数跳转
way1:使用 cscope 实现函数跳转(功能更齐全)
如果你的 Vim 配置了 +cscope 支持(可以通过
:version 命令查看),你可以使用 cscope 来进行函数跳转。
1. 生成 cscope 数据库:
在你的项目目录中,生成 cscope
数据库文件。打开终端,进入项目目录,执行: 1
cscope -Rbq
b:生成数据库文件。
q:启用快速查询。
2. 在 Vim 中启动 cscope:
启动 Vim 后,使用以下命令打开 cscope 数据库:
1 | :cs add cscope.out |
这将加载刚才生成的 cscope 数据库。
3. 进行函数跳转:
使用
:cs find c <function_name>查找并跳转到某个函数的定义位置。使用
Ctrl-]跳转到光标所在函数的定义。:f查看当前跳转到了哪个文件中
使用
:tjump/函数名使用
Ctrl-T返回到跳转之前的位置。
way2:使用 tag 文件实现函数跳转(基于 ctags)【推荐】
另一个常用的跳转方式是使用 ctags 来生成标签文件,这可以在 Vim 中实现函数的跳转。
1. 安装 ctags:
如果你没有安装 ctags,可以通过包管理器安装:
1 | sudo apt-get install exuberant-ctags |
2. 生成标签文件:
在项目根目录下运行以下命令来生成标签文件:
1 | ctags -R . |
- R:递归生成所有源代码文件的标签。
3. 在 Vim 中启用 tag 文件:
打开项目后,Vim 会自动加载当前目录下的 tags 文件。你可以使用以下命令手动加载:
在项目根目录启动 Vim:
1 | vim |
1 | :set tags=./tags; |
4. 跳转到函数定义:
将光标移动到你想跳转的函数名上,然后按 Ctrl-]
跳转到该函数的定义。
如果要返回到之前的位置,按 Ctrl-T。
你还可以使用 :tag <function_name>
跳转到函数定义。
更新 tag
第一种方法是使用 vim 插件
vim-gutentags,它会在保存文件时,自动在后台增量更新 tags
文件。
第二种方法是手动增量更新 tags 文件:
1 | ctags -R -a . |
-a 参数表示追加模式,这样可以避免每次都重新生成整个 tags
文件。
工程目录下查找某个函数名
grep -r "函数名" path
grep -rn "函数名" path # n: 显示行号
grep -r "待查找内容" --include="*.c"
6. 打造最强vim ide
安装工具 vim 插件管理工具:
1 | git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim |
然后把事先准备好的 .vimrc 文件放到 home
目录下,获取链接:https://pan.quark.cn/s/84d039d2ffc2
1 | cp /path/to/your/.vimrc ~/.vimrc |
打开 vim,执行以下命令安装和查看插件:
1 | vim |
ctags
安装 ctags:
1 | sudo apt-get install exuberant-ctags |
每个工程目录下生成 tags 文件:
1 | ctags -R . |
常用的快捷键有两个:
Ctrl-]:跳转到光标所在函数的定义。Ctrl-T:返回到跳转之前的位置。
cscope
ctags 只能跳转到函数定义,无法跳转到函数调用处,而 cscope 可以实现这两个功能。
安装 cscope:
1 | sudo apt-get install cscope |
每个工程目录下生成 cscope 数据库文件:
1 | 下面的命令会生成 3 个文件: cscope.out、cscope.in.out、cscope.po.out |
为了方便使用,我们已经在.vimrc中配置好了 cscope
的快捷键:
1 | "nmap <C-_>s :cs find s <C-R>=expand("<cword>")<CR><CR> |
常用快捷键说明:fn + Fx
F5:查找符号(变量、宏等)F6:全工程查找光标下的字符串(其中就包含了函数调用处)F7:全工程查找函数调用处
找到后,会自动打开底部窗口显示查找结果,输入下面的命令后就可以通过hjkl键在结果中进行上下选择:
1 | :copen |
找到想去的地方后,按回车键 Enter 就可以跳转过去。

输入下面的命令关闭窗口:
1 | :cclose |
tagbar
.vmrc中已经配置好了 tagbar 插件
- 打开 tagbar 窗口:
1 | :TagbarToggle |
- 关闭 tagbar 窗口:
1 | :TagbarClose |
nerdtree
用于左侧显示目录树
.vmrc中已经配置好了 nerdtree 插件
动态语法检测
.vmrc中已经配置好了 Ale
插件,左侧显示语法错误,其中x表示错误,w表示警告,
:ALEFix可以自动修复一些简单的语法错误。
YCM 代码自动补全
.vmrc中已经配置好了 YouCompleteMe 插件,该插件对 vim
的版本号有要求。
同时还需要安装一些依赖:
1 | sudo apt-get install build-essential cmake vim-nox python3-dev |
检查 python 版本是否为 Python3:
1 | python |
接下来编译 YouCompleteMe:
1 | cd ~/.vim/bundle/YouCompleteMe |
编译完之后,还要把~/.vim/bundle/YouCompleteMe/third_party/ycmd/examples/.ycm_extra_conf.py文件复制到./.vim目录下:
1 | cp ~/.vim/bundle/YouCompleteMe/third_party/ycmd/examples/.ycm_extra_conf.py ~/.vim/ |
以及在.vimrc中添加了相关配置就行了。
LSP 自动补全
但是由于 YCM 需要各种 vim 版本要求、python 要求,没达到要求的还要重新编译,非常麻烦,所以推荐使用 LSP 方式来实现代码自动补全。
先安装clangd:
1 | sudo apt-get install clangd |
.vimrc中已经配置相关插件,:PluginInstall安装完插件后,在你的
linux 工程目录下创建一个compile_commands.json文件:
linux 内核工程下生成 compile_commands.json:
linux
的话推荐用scripts/clang-tools/gen_compile_commands.py
1 | make defconfig |
然后打开c文件,可以查看是否启用了 LSP 补全:
1 | :LspStatus |
其他C/C++ 项目生成 compile_commands.json:
可以使用cmake生成:
1 | cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=ON .. |
这会在项目根目录下生成一个 compile_commands.json 文件,clangd 使用该文件来获取编译选项。
如果你的项目不是用 cmake 构建的,一般 clang
会自动生成gen_compile_commands.py,可以利用该工具来生成
compile_commands.json:
1 | cp /path/scripts/gen_compile_commands.py |
7. 编译
反汇编
编译完二进制文件.o等二进制可执行文件后,可以使用
objdump -d 反汇编查看函数的汇编代码。
1 | objdump -D myfile.o > myfile.s |
8. 硬件参数查询
查看 CPU 数、numa数、qemu 线程 pid
1 | lscpu |
qemu 进入monitor
1 | info cpus |
开关 SMT
SMT (Simultaneous Multithreading, 同时多线程)
也就是假设你的单 P (单 socket 槽)机器上有 64 个物理核,如果关 SMT的话,同一时刻只能有 64 个逻辑核,同一时刻也只能有 64 个线程。
但是当开
SMT后,可以启用超线程,把逻辑核翻倍,每两个逻辑核公用一套物理核上的资源,但是此时每个物理核上同一时刻可以跑
2 个逻辑核,同时跑 2 个线程。 开 SMT 后重新用lscpu查看 cpu
数,可以看到显示的 cpu online数量翻倍了。
可以通过以下方式查看 CPU 是否支持 SMT 超线程、以及当前是否开启了 SMT 超线程:
1 | cat /sys/devices/system/cpu/smt/active |
1 | akira@akira:~$ cat /sys/devices/system/cpu/smt/active |
9. tmux 使用
会话管理
新建会话
1 | tmux new -s <session_name> |
进入会话
1 | tmux a -t <session_name> |
查看会话
1 | tmux ls |
退出会话
1 | 快捷键:Ctrl + b, 然后按 d # 会话跟窗口分离,可以退出当前会话,但会话还在后台继续运行 |
切换会话
1 | tmux switch -t <session_name> |
重命名会话
1 | tmux rename-session -t <new_session_name> |
复制模式:解决鼠标没法上划的问题
进入:按ctrl+b,然后按[进入复制模式后,就可以用方向键或者鼠标滚轮上划查看之前的输出了
退出:按q退出复制模式。
分屏
分屏
1 | 划分上下两个窗格 |
切换窗口
1 | 切换到下一个窗口 |
窗口快捷键
1 | Ctrl+b %:划分左右两个窗格。 |
解决左右分屏后无法精准选中的问题
1 | vim ~/.tmux.conf |