一、Redis数据结构
1. string
1.1 基本操作:增删改查
创建:
set key valuesetnx key value:如果key不存在则设置,否则失败
查询
get keymget key1 key2:一次获取多个key的值
更新
set key value
删除
del key
1.2 底层实现
编码格式:
int:存储整数embstr:小于等于44字节的字符串(浮点型会被转换为字符串存储)raw:大于44字节的字符串
2. list
list就是一个列表
1 | [ |
2.1 基本操作
list是允许双端操作的,不是完全的先入先出,也不是完全的后入先出
创建
lpush key value1 value2:从左边插入rpush key value1 value2:从右边插入
查询
llen key:获取列表长度lrange key start end:获取指定范围的元素
更新
lpush key value1 value2:从左边插入rpush key value1 value2:从右边插入lpop key:从左边弹出rpop key:从右边弹出
删除
del keylrem key count value:删除指定数量的元素,时间复杂度O(n)ltrim key start end:删除指定范围的元素,时间复杂度O(n)
2.2 底层实现
ziplist:压缩列表,用类似数组的结构存储数据,修改效率低linkedlist:双向链表,修改效率高quicklist:ziplist和linkedlist的结合体
3. set
set适用于去重场景和交集场景,可以在点赞和共同关注等场景中使用
3.1 基本操作
创建
sadd key value1 value2:添加元素
查询
sismember key value:判断元素是否存在smembers key:获取所有元素的列表SUNION key1 key2:求并集,如用于共同关注的人
更新
sadd key value1 value2:添加元素srem key value1 value2:删除元素
删除
del key
3.2 底层实现
intset:整数集合,元素都是整数(有序的,整体来看不依赖set的顺序)hashtable:哈希表,元素都是字符串(无序的)
存在元素个数阈值,当元素个数小于512个时会用intset,否则会用hashtable
4. hash
4.1 基本操作
创建
hset key field1 value1 field2 value2:添加元素hsetnx key field value:如果field不存在则设置,否则失败
查询
hget key field:获取元素hgetall key:获取所有元素
更新
hset key field value:添加元素hdel key field:删除元素
删除
del key
4.2 底层实现
都是无序的
ziplist:压缩列表,用类似数组的结构存储数据,修改效率低hashtable:哈希表,元素都是字符串(无序的)
5. zset
5.1 基本操作
5.2 底层实现
ziplist:压缩列表,用类似数组的结构存储数据,修改效率低,查找速度为O(n)skiplist:跳表,类似于二分法,查找速度为O(logn)
为什么用跳表而不用红黑树?
跳表跟红黑树的查询时间复杂度都是O(logn),但是跳表的实现更简单,而且跳表的范围查询效率更高;而平衡树插入和删除涉及旋转等操作,较为复杂
但是跳表的层数比较高
跳表插入一个数的层高是随机的,一开始默认1层,然后每增加一层的概率都是25%,最高为32层
二、Redis基础知识
redis常用在热点词、排行榜、分布式锁setnx等场景中
1. redis的优点
- 读写性能高:redis是基于内存的,读写性能高
- 数据结构类型多:支持多种数据结构,如string、list、set、hash等
- 功能:支持事务、哨兵模式、主从复制、集群等功能来保证数据的安全性和高可用性
2. redis的单线程与多线程
redis主要处理逻辑是单线程的,主要的数据crud是短平快的,本身不会消耗很多时间,而如果像mysql一样用多线程还要考虑资源竞争、线程上下文切换、同步机制等开销,增加了维护难度,提高了系统复杂度,得不偿失:
- 数据读写上:redis数据是通过内存的,所以瓶颈不在cpu
随着高并发场景的普及,单核cpu也逐渐不够用了(不过redis的多线程是默认关闭的,可以在redis.config配置文件中打开)
redis的主要瓶颈在I/O处理上,所以采用epoll多路复用用+reactor模式来提高I/O处理效率。
- 解包、回包用的是多线程
- RDB全量备份时属于耗时操作,开一个单独进程来执行
3. 缓存穿透、缓存击穿、缓存雪崩
- 缓存穿透:Redis和MySQL都没有这个key
- 缓击击穿:某个热点key失效
- 缓存雪崩:大量key同时失效
3.1 缓存穿透
缓存穿透是指查询一个一定不存在的数据,也就是redis和mysql都不存在这个key,会导致数据库压力过大
解决方案:
1)布隆过滤器
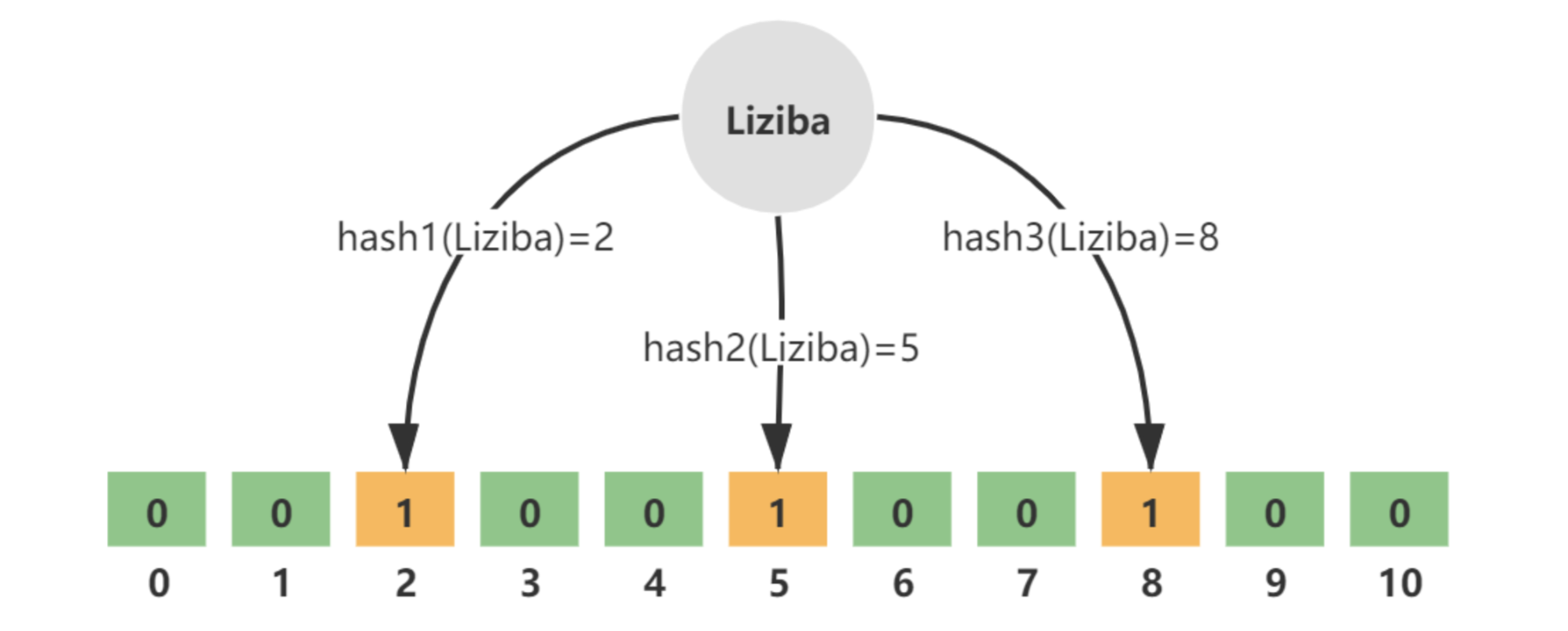
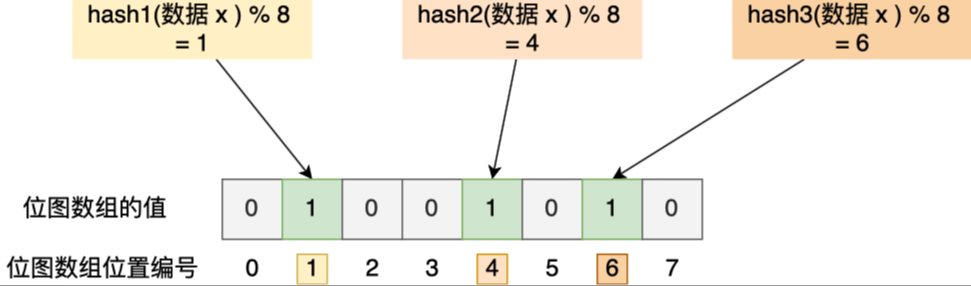
布隆过滤器将可能存在的key的哈希存到一个足够大的位数组中
- 能通过布隆过滤器的key不一定存在
- 但是不能通过的key一定不存在
2)限流策略:漏斗算法、令牌桶
- 漏斗算法:漏斗的流出速度是固定的,如果流入速度大于流出速度,那么就会溢出
- 令牌桶:固定速率往桶里放令牌,请求来了就拿一个令牌,如果没有令牌则拒绝请求
- 优点:空闲时攒着令牌,用于应对突发流量
3.2 缓存击穿
缓存击穿是指某个热点key失效,导致大量请求直接打到数据库
解决方案:
1)热点数据永不过期
对于某些热点数据,可以设置永不过期
2)延迟过期时间
设置窗口时间,窗口时间内key被频繁访问则延长过期时间
3.3 缓存雪崩:常见于主redis宕机
缓存雪崩是指大量key同时失效,导致大量请求直接打到数据库
解决方案:
如果是普通失效,可以通过设置随机过期时间来避免同时失效,也可以类似于缓存击穿的解决方式设置窗口时间或永不过期
如果是主redis宕机,可以通过从redis来解决
1)主从redis
设置主从redis集群,当主redis宕机时,可以通过重新选举新的主redis来继续提供缓存服务
2)熔断
当主redis宕机时,可以通过熔断来避免大量请求直接打到数据库,直接关掉缓存相关的一些次要服务,保证核心功能的正常运行
4. redis持久化:RDB和AOF
redis持久化是通过RDB和AOF实现,其中RDB(二进制文件)是使用快照可持久化,AOF(文本文件)是追加型日志;其中RDB在宕机时会出现较大的丢失,而AOF是用于恢复的,用默认everysec的话最多允许1s的数据丢失
1)RDB
RDB是全量保存,操作量大,所以一般5min保存一次
2)AOF
AOF是追加,操作量小,所以一般频率较高(1s)
3)RDB和AOF的混合使用
RDB是做备份用的,从缓存可以直接恢复,会比从db恢复快,所以一般也建议开启RDB。
在恢复时先将RDB的二进制数据以二进制的格式写入新的AOF文件中,其余的没来得及全量备份的数据可以通过以前的AOF来恢复
之后追加进AOF的新数据继续以AOF的文本格式追加
5. redis的过期策略
5.1 定时删除
每个key都会有一个定时器,到期后会被删除
缺点:每个key都要维护一个定时器,占用内存
5.2 惰性删除
当用户访问取key时才删除
缺点:如果长期无操作则会逐渐导致内存泄漏
5.3 定期删除
适合cpu能力较差的,所有key定期检查是否过期
缺点:及时性有限,可能会存在有key过期了但还没被删除的情况
5.4 定期+惰性
redis采用的是定期+惰性的策略
6. redis的内存淘汰策略
内存回收触发时机:每次读写时都会检查内存是否超过限制,如果超过则会触发内存回收
6.1 noeviction不淘汰(默认的)
redis默认采用不淘汰的方式,当内存超过限制时拒绝写入
6.2 lru:淘汰最久未使用的key
lru是最久未使用的key
但是redis使用的是近似lru,因为标准lru是维护双端链表,内存成本大
近似lru是通过随机采样来实现的:每次淘汰时随机选取一部分key,然后淘汰其中最久未使用的key(根据最近使用时间排序)
6.3 lfu:淘汰使用频率最低的key
lfu记录上次访问的时间戳和累计访问次数,每次淘汰时选取访问次数最少的key
其中如果一段时间内没有被访问,那么该key的访问次数会逐渐衰减
lfu相比lru好处在于:lru按照最近使用时间排序,可能会删除某个热点key,而lfu则是按照访问次数排序
6.4 random:随机淘汰设置了过期时间的key
7. redis的使用场景
7.1 redis+mysql保持一致性的方式:旁路缓存
旁路缓存遵循读更新redis、写删除redis的原则
- 读:
- 先读redis
- 如果没有再读mysql,然后重新写入redis
- 写:
- 先写mysql,再删除redis
- 过期兜底:设置一个较短的过期时间,避免数据不一致
7.2 redis在秒杀中的作用:削峰
将redis当做消息队列使用,记录库存,当库存量少于0时,直接拒绝客户端请求
7.3 redis的分布式锁
加锁way1:set+nx&px
1)不直接使用setnx的原因:无法保证原子性
在redis中,如果使用setnx无法直接设置过期时间,必须setnx+expire
但是这样两个指令就无法保证原子性了
因此一般使用set+nx和px参数
nx:如果key不存在则设置px:设置过期时间
1 | set lock_key unique_value nx px 10000 |
2)解锁:用lua保证原子性
解锁有两个操作:
- 判断锁的unique_value是否为准备执行解锁的客户端(key是锁的名字,values是owner保证原子性的,是锁持有者的id)
- 然后再解锁
需要执行两个操作,不符合原子性,所以要用lua脚本来保证原子操作(lua本身不是原子操作,但是redis是单线程,所以可以保证操作的原子性)
加锁way2:redlock红锁
1)用红锁的原因:单点故障锁尚未同步到子节点
集群下有多个redis节点,客户端向主节点申请加锁,此时如果主节点单点故障了,新的主节点并没有同步锁的信息,导致其他客户端可以继续加锁
2)解决方案:红锁保证超过半数子节点成功加锁
- 记录客户端刚发出加锁请求的时间点为t1
- 客户端加锁操作不仅对主节点进行,还需要同时向超过半数的节点成功加锁
- 拿到半数用户加锁的时间点t2-t1<锁过期时间,则认为加锁成功
- tips:如果完成加锁操作后锁已经过期了,那么也没有意义
8. redis的集群模式:主从复制模式、哨兵模式、hash切片集群
redis提供三种集群模式:主从复制模式、哨兵模式、hash切片集群
8.1 主从复制模式:读写分离
多个节点,读写分离降低主节点压力,该模式下,主节点宕机不会自动选举新的主节点,因此需要手动恢复
且数据同步跟主节点返回操作结果给客户端之间是异步的,所以可能会有数据不一致的情况
redis主从复制的方式:
redis主从节点之间的连接方式是长连接的
- 新节点加入:全量复制:主节点将数据全部复制给新的从节点
- 旧的从节点:增量复制:主节点将增量数据复制给旧的从节点,从节点掉线后如果落后的不多也会用增量复制

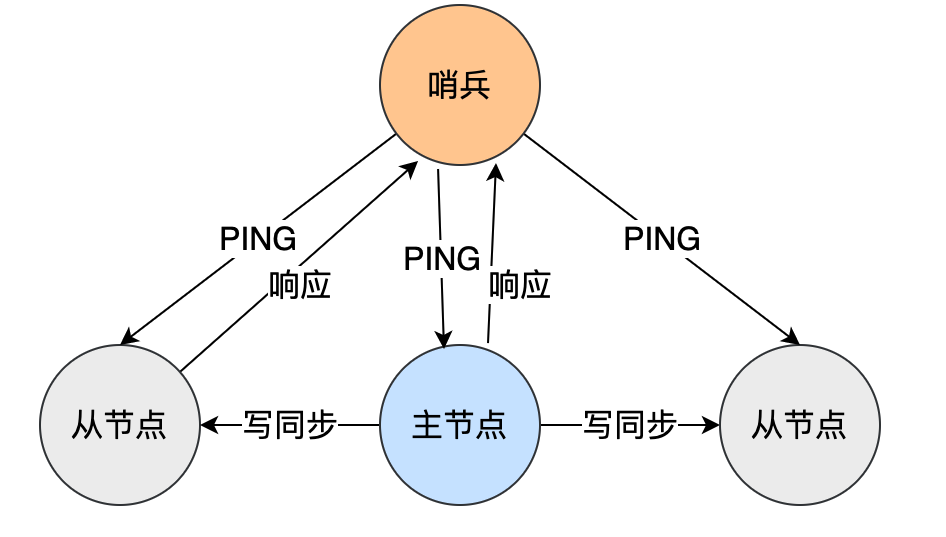
8.2 哨兵模式:自动选举新的主节点
哨兵模式通过新增一个哨兵节点来监控主节点的状态,当主节点宕机时,哨兵节点会自动投票选举新的主节点,实现主从节点故障转移
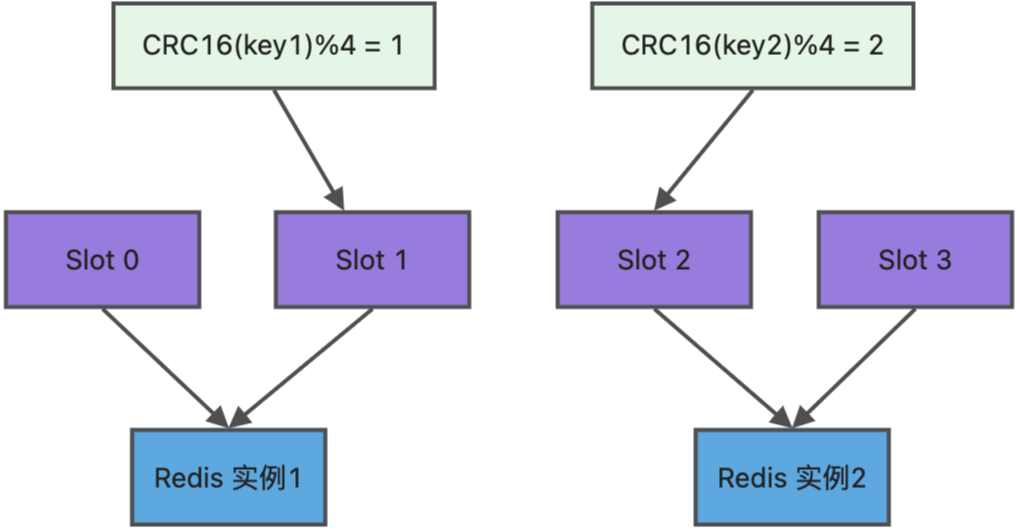
8.3 hash切片集群:数据分片
当一台机器无法承载时,可以通过切片方案将数据分布在不同机器上
redis没有一致性哈希的概念,而是使用2^14的哈希槽来实现的切片