
一、内核缓冲区Page Cache
进程在调用write函数写入文件描述符时,其实不是直接写入文件,而是
- 先中段到内核空间
- 然后再由内核空间写入内核缓冲区Page Cache(因为内核缓冲区相较于磁盘I/O速度更快)
- 最后内核会在适当的时机将内核缓冲区的内容写入磁盘
通过这种机制,可以减少操作磁盘I/O的次数,提高磁盘I/O效率(当然也可以通过mmap函数将文件映射到内存中,这样就可以直接操作内存,内存中的操作既快速,又不用经过内核态<-->用户态的切换,更加高效)
如果想立即将内核缓冲区的内容写入磁盘,可以调用fsync函数(调用fflush函数也会将缓冲区的内容强制写入磁盘,而不等待缓冲区满再刷新)
二、零拷贝技术:mmap
磁盘相对于计算机中的CPU、内存来说,属于慢速设备,因此针对磁盘的优化,有我们上述讲到的通过内核态中的缓冲区Page Cache减少I/O访问次数,还有通过零拷贝技术来减少数据在内核态和用户态之间的拷贝次数
如果通过中断的方式,当我们发生系统调用read时,内核会将磁盘中的数据拷贝到内核缓冲区(第一次拷贝),然后再将内核缓冲区的数据拷贝到用户缓冲区,这样就发生了两次拷贝
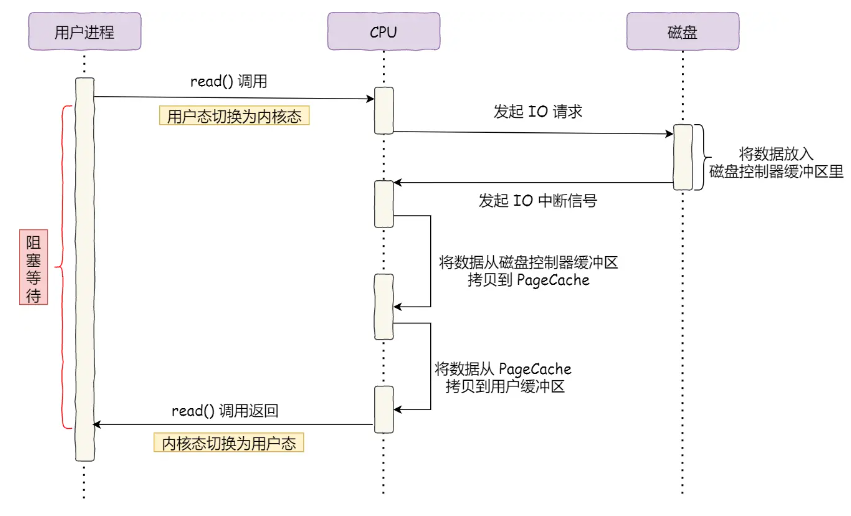
也就是说在大量数据拷贝过程都需要CPU参与搬运,这样会浪费CPU资源,降低效率
因此进一步可以通过DMA直接内存访问技术进行优化:
在不占用CPU资源的情况下(此时CPU可以执行其它任务),将数据从磁盘拷贝到内核缓冲区
当DMA读取了足够多的数据,再通知CPU将数据从内核缓冲区拷贝到用户缓冲区,这样就只发生了一次拷贝
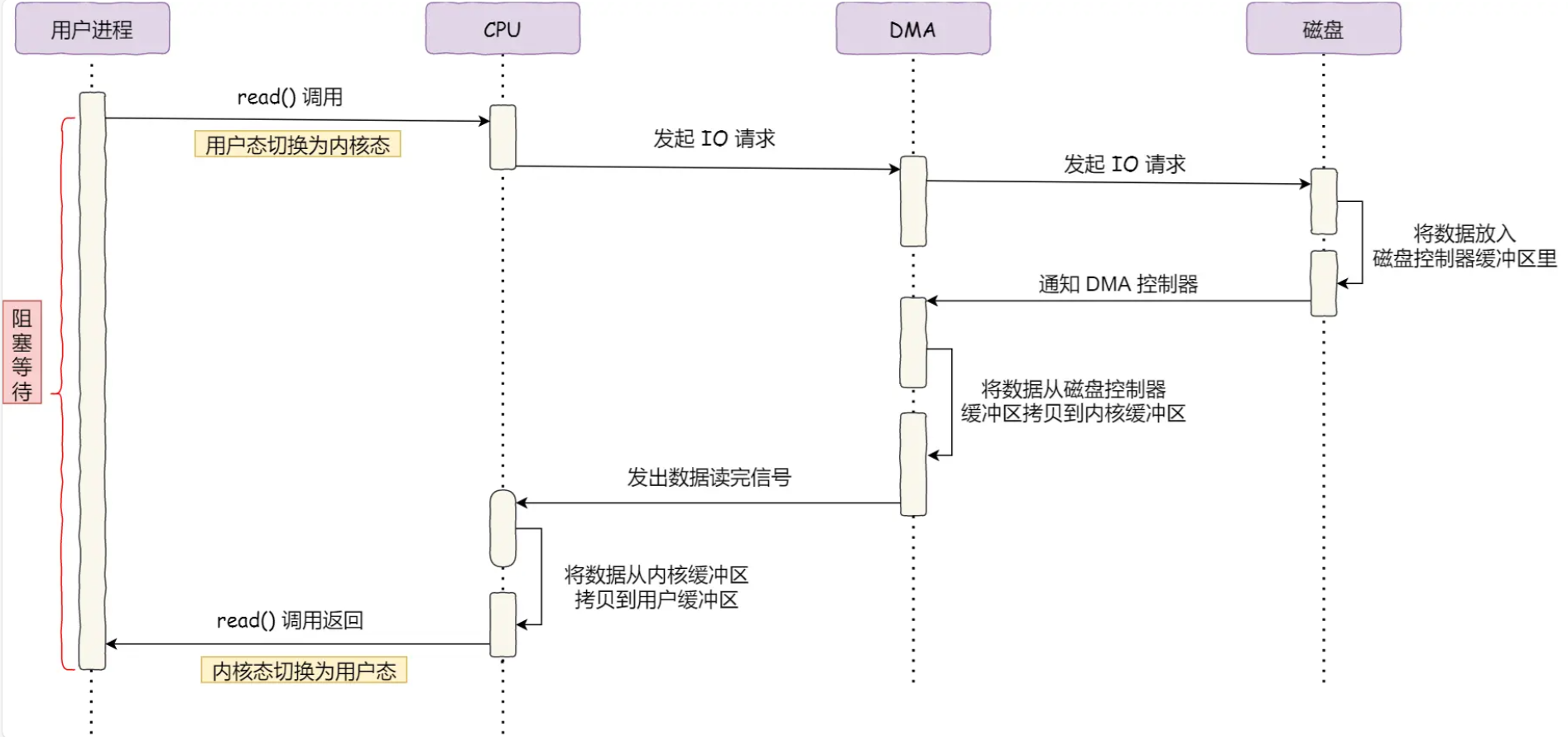
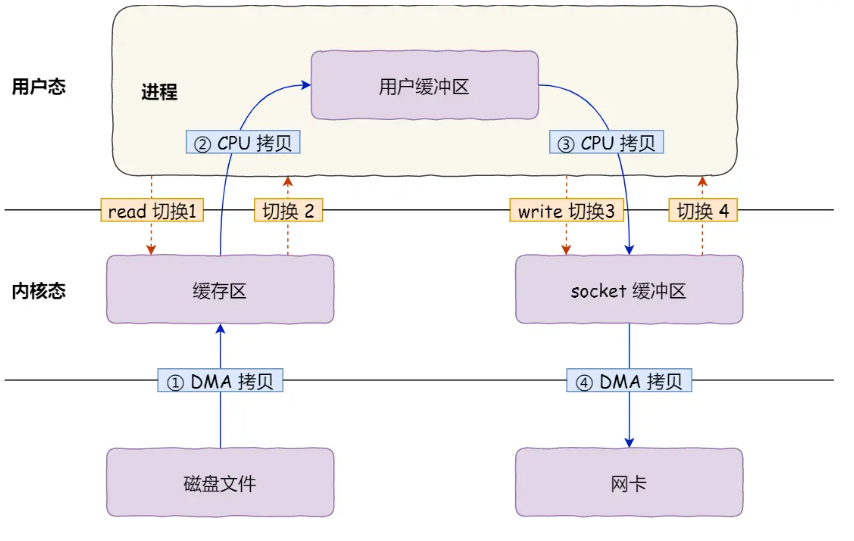
即使采用DMA技术,还是需要通过CPU进行一次拷贝,具体通过read和write的流程如下所示(各发生2次用户态<-->内核态的上下文切换,一次切换需要耗时几十纳秒到几微秒;以及各发生一次DMA拷贝+一次CPU拷贝):
'''shell read(file, buffer, size) write(socketfd, buffer, size) '''
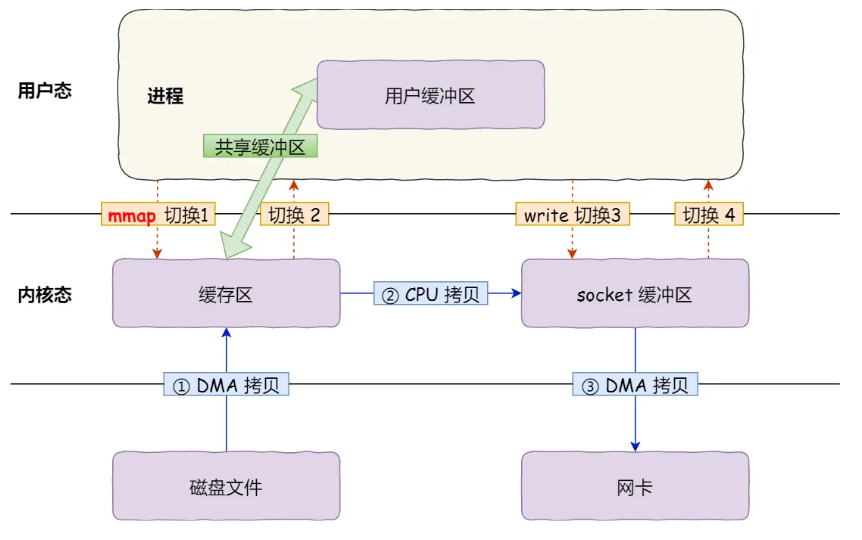
而实际上,多次拷贝是没必要的,我们可以通过mmap函数将文件映射到内存中,使read和write直接操作共享的内核缓冲区,这样就可以减少一次拷贝,但也不是完全的零拷贝,具体流程如下:
'''shell buf = mmap(file, size) write(socketfd, buf, size) '''
真正的零拷贝是Linux上提供的sendfile函数,它可以直接将文件描述符之间的数据拷贝,而不需要经过用户态,完全存在内核态中,只经过2次拷贝,具体流程如下:
'''shell sendfile(out_fd, in_fd, offset, size) '''
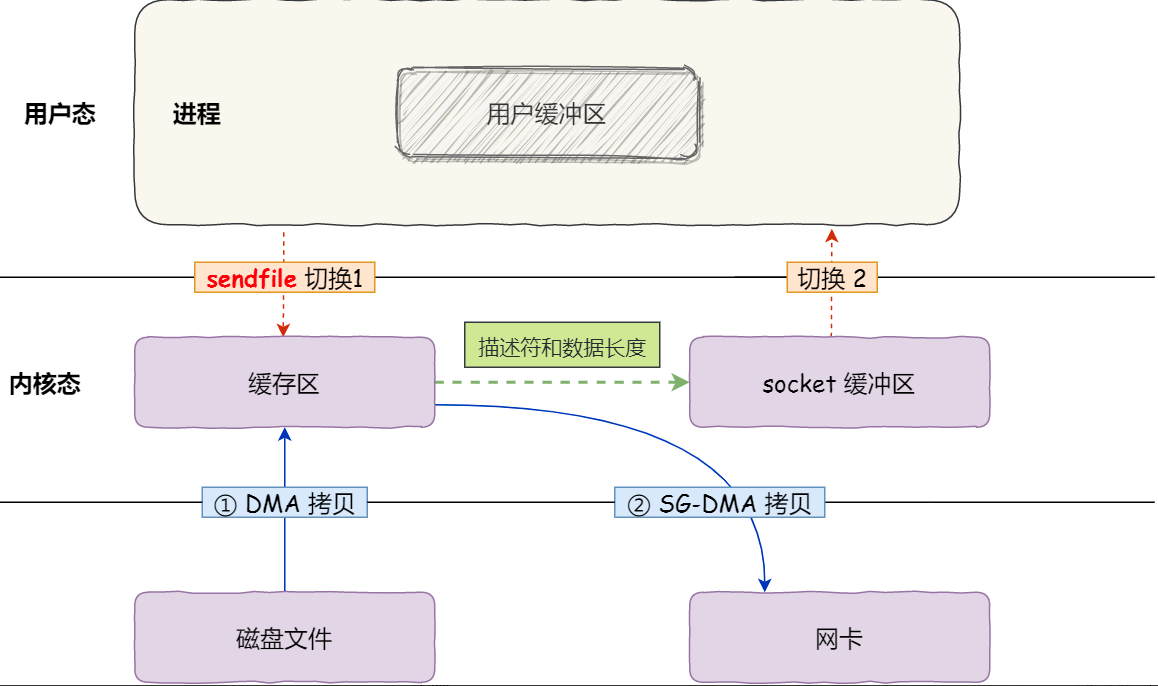
参考:什么是零拷贝?
三、I/O多路复用技术
3.1 Linux中的五中I/O模型
- 阻塞I/O:调用
socket.read()或socket.write()时,如果没有数据可读或写,会一直阻塞等待,直到有数据可读或写- 适合计算密集型,因为计算密集型消耗的是CPU资源
- 非阻塞I/O:不断轮训查看数据是否准备好,所以非阻塞I/O也不会交出CPU
- 适合传视频,一直占用CPU减少线程切换的成本
- I/O复用:通过
select、poll、epoll等函数,可以同时监听多个文件描述符,当其中任何一个文件描述符就绪时,就可以进行读写操作(监听的文件描述符本身也是阻塞的) - 信号驱动I/O:通过信号来通知应用程序I/O已经完成
- 异步I/O:通过
aio_read、aio_write等函数,可以在I/O操作完成后通知应用程序(应用程序发起I/O后可以直接进行其它操作,不用等待I/O完成)
在文章WebServer学习3:socket编程与epoll实现I/O复用中已经有详细介绍,这里不再赘述
四、事件驱动模型
在文章WebServer学习4:并发事件驱动模式Reactor和Proactor中已经有详细介绍,这里不再赘述