
一、CPU执行过程
1.1 CPU基本硬件结构
我们直到,计算机主要是由CPU、内存、I/O设备组成的,操作速度CPU Cache > 内存 > 硬盘
- CPU Cache有三级缓存,分别是L1 > L2 > L3,L1速度最快、容量最小、价格最昂贵
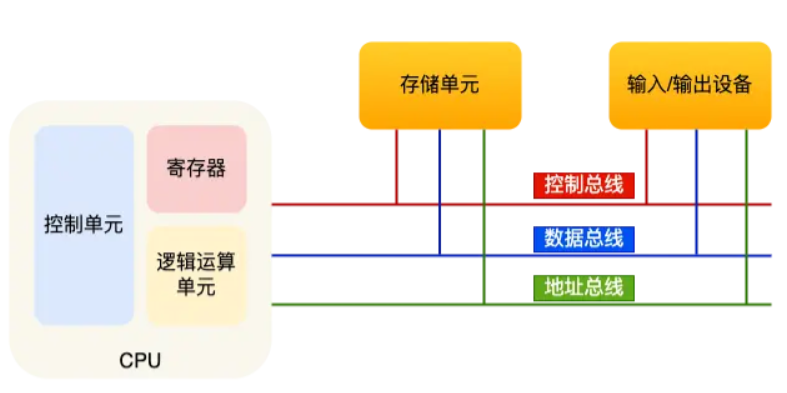
而CPU是计算机的核心部件,它负责执行指令、控制操作等,其执行速度极快,且速度与时钟周期息息相关。CPU的基本硬件结构如下:
- 寄存器:CPU内部的高速存储器,用于缓存指令、数据等。
- 通用寄存器:存放数据
- 程序计数器:存放下一条指令的地址
- 指令寄存器:存放当前指令
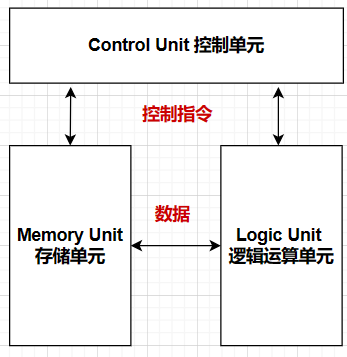
- 逻辑单元ALU:负责执行算术运算、逻辑运算、数据传输、条件分支等
- 控制单元:负责控制指令的执行
- 负责按照地址从内存中取出指令
- 负责跳转操作
1.2 CPU寻址与位宽的关系
1.2.1 位宽
位宽是指CPU一个时间周期能处理的数据位数,例如32位或64位,位宽越大,CPU处理数据的能力越强,但同时也会增加成本。
1.2.2 寻址
寻址是指CPU访问内存的方式,是由地址总线决定的,因此寻址能力与位宽是无关的,因为位宽管的是数据。
1.2.3 位宽与寻址的关系
场景:
- 当CPU需要从内存中读取数据到寄存器 或者 写入数据到物理内存时
流程:
- CPU会先通过地址总线指定需要访问的物理内存地址
- 在指定的物理内存地址通过数据总线进行读取或写入操作
1.3 CPU执行指令过程
CPU执行指令的一个指令周期过程如下:
- step1:CPU读取程序计数器中的指令地址(内存地址)
- step2:CPU根据指令地址,交由控制单元操作地址总线去访问指定内存地址,读取指令
- step3:CPU将读取到的指令存放到指令寄存器中
- step4:程序计数器完成上述操作后,自增指向下一条指令,其中自增的步长(字节)取决于CPU位宽,一般为32位或64位
- step5:CPU根据指令寄存器中的指令,解析指令类型和参数,对于计算指令,将参数从通用寄存器中取出,交由逻辑运算单元ALU执行计算
二、用户态与内核态
2.1 用户态与内核态
OS中的内存根据权限划分为两个空间:
- 用户空间(User Space):用户程序运行的空间(权限小,执行普通操作)
- 内核空间(Kernel Space):操作系统运行的空间(权限大,执行访问磁盘、内存分配、网卡、声卡等敏感操作需要进行安全校验) -内核态是用于应用程序跟操作系统、硬件连接的桥梁,进行系统调用、中断处理等操作。拥有最高级别的操作权限,可以直接访问如网卡、硬盘、内存等资源
一个运行中的进程/程序,在执行中有可能处于用户态或者内核态,因此这里就涉及了两个空间之间的切换:
- 用户态--->内核态:当用户程序需要进行外部资源申请时,需要切换到内核态,一般有以下几种情况:
- 系统调用:用户程序通过系统调用请求操作系统提供服务(软中断)
- 异常:用户程序执行过程中出现异常,如除零操作
- 中断:外部设备发生中断,需要CPU处理
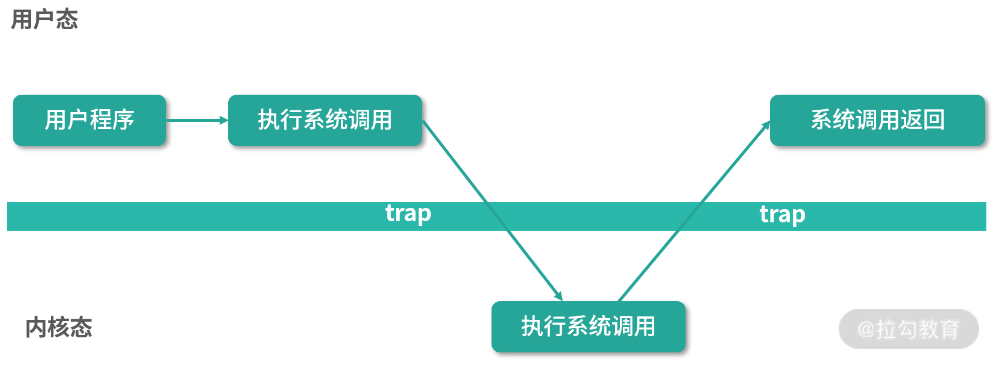
2.1.1 系统调用
一次系统调用一般会触发两次CPU上下文切换:
- 第一次是用户态->内核态,要将寄存器、堆栈信息等保存到内核栈中,用于切回来时程序的恢复
- 第二次是内核态->用户态,要将内核栈中的信息恢复到用户栈中,用于程序的继续执行
1)系统调用的类型
系统调用一般有以下几种:
- 进程控制:如创建进程(
fork)、终止进程(exit) - 文件操作:如打开文件(
open)、读写文件(read/write)、关闭文件(close) - 设备(外设)操作:如读写设备(
read/write) - 通信:如创建管道(
pipe)、消息队列(msgget)、mmap
以申请内存(malloc)为例,当C++中调用malloc函数时,实际上会执行系统调用:
- brk:对于较小的内存申请,会调用
brk系统调用 - mmap:对于较大的内存申请,会调用
mmap,mmap申请的是虚拟内存而不是物理内存,当出现第一次访问时,会发现该处的虚拟内存没有映射到物理内存,此时会发生缺页中断,操作系统才会将虚拟内存映射到物理内存中
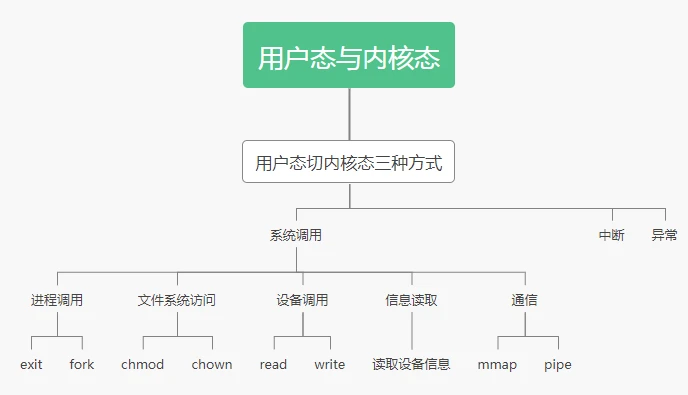
2)系统调用的过程
正常情况下,程序是运行在用户态内存空间中的
当程序需要执行系统调用时,会发现其权限不够,此时会产生中断Trap(切换到内核态是通过中断实现的)
然后CPU跳转到内核空间执行系统调用
在内核态处理完后,再次产生中断Trap,并将系统调用的结果返回给用户空间
2.1.2 中断
1)中断的概念
中断是指CPU在执行程序时,由于外部事件的发生(通常由IO设备触发),当CPU收到中断号时,CPU暂停当前程序的执行,转而去执行相应的中断处理程序,处理完后再返回原来的程序继续执行。
操作系统会注册中断号以及其对应的中断处理程序(也就是注册后存在中断向量表中),当中断发生时,CPU会根据中断号找到对应的中断处理程序,并执行。
其中中断向量表的一个节点如下:

具体执行中断的步骤如下(以键盘按下为例):
- 硬件:键盘按下,会通过中断控制器发送中断信号 n给CPU
- CPU:收到中断信号 n后,会去中断向量表中寻找第 n 个中断描述符,从中断描述符中找到中断处理程序的地址
- CPU:通过压栈操作保存当前程序的状态(原来的程序地址、原来的程序堆栈、原来的标志位),然后跳转到中断处理程序的地址执行
- 中断处理程序执行完后,再通过出栈操作恢复原来的程序状态,继续执行原来的程序
2)操作系统需要中断的原因
- 针对硬件中断:设想一下,如果没有中断机制,那么CPU在执行程序时,还要不断的去轮询外设是否有数据到来,导致CPU的利用率非常低。
- 针对软件中断:如果一个应用程序触发了某个操作,需要从用户态切换到内核态,如果没有中断机制,那么CPU会进入盲等待状态(等待寄存器空闲)。(中断机制可以让CPU在等待时,去执行其他程序)
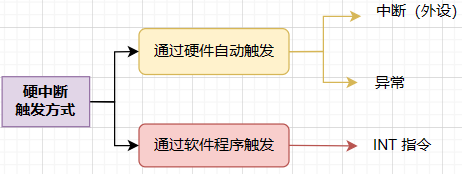
3)CPU触发中断的三种方式
- 通过中断控制器(外设)给 CPU 的
INTR引脚发送信号,CPU 从中断控制器的一个端口上读取中断号。- 比如按下键盘的一个按键,最终会给到 CPU 一个 0x21 中断号。
- CPU
执行某条指令发现了异常,会自己触发并给自己一个中断号
- 比如执行到了无效指令,CPU 会给自己一个 0x06 的中断号。
- 系统调用执行
INT n指令,会直接给 CPU 一个中断号 n- 比如触发了 Linux 的系统调用,实际上就是执行了 INT 0x80 指令,那么 CPU 收到的就是一个 0x80 中断号。
4)硬件中断和软件中断
硬件中断和软件中断都属于硬中断,只是触发方式不同。
5)硬中断和软中断
由于中断会打断内核中进程的正常调度运行,所以要求中断服务程序尽可能的短小精悍;但是在实际系统中,当中断到来时,要完成工作往往进行大量的耗时处理。
所以一般 Linux 会把中断分成上下两半部分执行,上半部分处理最简单的逻辑(硬中断),下半部分直接丢给一个软中断异步处理。
比如我们进行网卡的数据包处理时:
- 当网卡收到一个数据包时,将数据包放到内核的缓冲区中,然后会触发一个硬中断
- 硬件中断告诉 CPU 有数据包到来并触发一个软中断
- 软中断会在内核态异步处理数据包的解析(如完整性、校验等)
硬中断
上述3)中提到的三种方式全是硬中断(包括中断、异常以及 INT 指令这种软件中断)。整个中断机制是纯硬件实现的逻辑,不管触发它的是谁,所以通通叫硬中断。
微观上来说,CPU 在每一个指令周期的最后,都会留一个 CPU 周期去查看是否有中断,硬中断处理耗时短的操作
软中断
软中断是处理硬中断后,延时处理具体的耗时的工作。
主要区别
- 硬中断是由硬件设备直接触发,通常是即时的,需要快速响应。
- 软中断是由内核代码触发,可以是延迟的,用于处理那些不需要立即响应的任务。
2.1.3 异常
异常是指程序在执行过程中,由于程序错误或CPU故障等原因,导致程序无法继续执行,CPU根据异常类型查找异常向量表,找到对应的异常处理程序,进行处理。
2.2 用户态与内核态的切换的具体实现
以Linux系统系统为例,操作系统会为每个进程分配出内核空间和用户空间
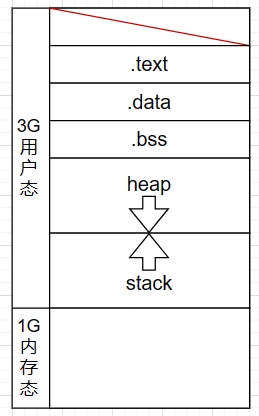
当发生切换时:
CPU会涉及上下文切换,将用户态原来在CPU中的程序计数器和栈指针等寄存器的值保存到内核态的内核栈中,以便最后内核态执行完逐步出栈后,能够恢复到用户态的执行状态
保存完后再更新CPU的程序计数器和栈指针等寄存器的值,将其变为内核态的值
然后才跳转到内核态执行系统调用
系统调用结束后再次进行上下文切换,恢复CPU的寄存器的值,将其变为用户态的值
系统调用过程中,并不会涉及到虚拟内存等进程用户态的资源,也不会切换进程。
系统调用过程通常称为特权模式切换,而不是进程上下文切换。
2.3 用户态与内核态下的线程问题
实际系统中会存在用户态线程和内核态线程的问题,关于这部分的线程问题将在下面的进程管理中详细介绍。
参考资料:
三、进程管理
3.1 进程与线程
3.1.1 进程与线程的基本区别
- 进程:资源分配的基本单位
- 线程:CPU调度的基本单位
我们执行一个程序时,实际上是操作系统为我们创建了一个进程,一个进程中可以有多个线程存在
- 操作系统的三大资源
- CPU
- 内存
- 文件描述符
- 进程分配的资源
- 内存空间:代码段、数据段、堆、栈等
- 文件描述符:打开的文件、网络连接等
- CPU时间片
- 线程分配的资源
- 寄存器:通用寄存器、程序计数器等
- 栈:线程独有的栈空间(从进程的用户态堆中分配出来的)
- CPU时间片
从最基本的关系来说,多线程可以共享其进程的资源(虚拟内存空间、文件描述符资源、信号处理器...),各个线程之间独立地拥有自己的栈空间和寄存器
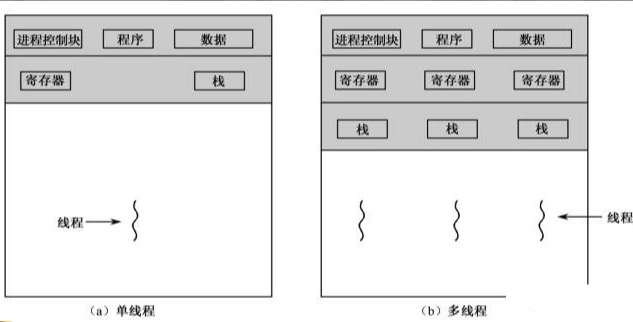
1)线程的优缺点
- 优点:开销小、通信方便
- 创建快
- 终止快
- 切换快:同一进程的线程切换不需要切换资源,只切换独有的栈空间和寄存器
- 不用重新加载CPU页表缓存TLB:进程切换需要改变虚拟地址空间重新加载页表,会导致TLB(CPU中的页表缓存)失效
- 通信方便:同一进程的线程共享内存空间,数据传输不经过内核
- 缺点:单个线程出错会导致整个进程崩溃
2)进程的优缺点
- 优点:稳定性高
- 独立性:进程之间独立,一个进程出错不会影响其他进程
- 资源独立:进程之间资源独立,一个进程的资源不会被其他进程访问
- 缺点:开销大、通信复杂
3.1.2 进程与线程的结构描述
进程和线程的结构称为进程表和线程表,其中包含了进程和线程的基本信息,存储于内核空间中。
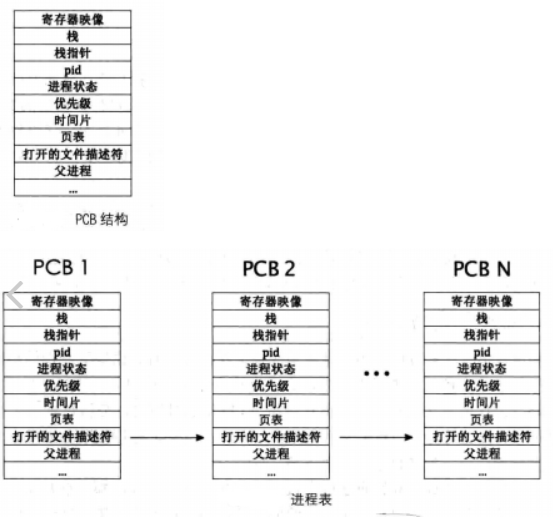
1)进程控制块的结构:PCB
在操作系统中,每个进程具有唯一标识PCB(Process Control Block)来描述一个进程的基本信息,进程的PCB是系统感知进程的唯一实体,包括:
- PID:进程的唯一标识
- Name:进程的名字
- State:进程的状态(运行、就绪、阻塞等)
- Priority:进程的CPU抢占优先级
- 资源I/O分配:内存地址、虚拟空间地址、打开和使用的文件描述符等(进程间是通过页表的方式隔离地址空间的)
- CPU信息:主要是记录切片中断保存现场的信息,但是其实PCB不够大存不下,所以会有内核栈来配合存放这些信息
- ...... 要频繁转换
2)线程控制块的结构:TCB
线程表中存放的信息与进程类似,包括:
- Thread ID:线程的唯一标识
- State:进程的状态(运行、就绪、阻塞等)
- Priority:进程的CPU抢占优先级
- CPU信息:程序计数器等寄存器的值
3.1.4 进程与线程的状态类型
我们知道,CPU调度采用的是时间切片的方式,所以需要有多个状态来描述进程和线程的状态:
- 创建状态
- 就绪状态:维护一个就绪队列,等待CPU调度
- 运行状态:该时刻正在占用CPU
- 阻塞状态:等待某个事件的发生,如I/O磁盘操作读取数据、打印机响应等,避免占用CPU
- 挂起状态:当进程/线程内存空间搬至外存、
sleep、Ctrl+Z主动挂起时会进入挂起状态- 就绪挂起:内存空间搬至外存(硬盘),但只要重新进入内存就立刻执行
- 阻塞挂起:等待某个事件的发生,但只要事件发生就立刻执行w
- 终止状态:进程或线程执行完毕
各状态之间具有相互转换的关系:
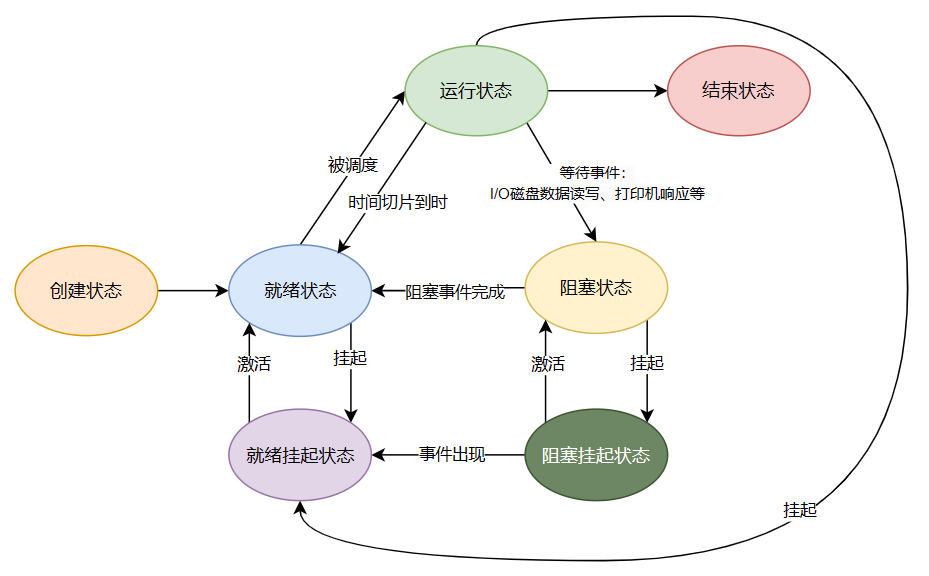
1)创建状态
- 申请PCB/TCB,并初始化
- 分配内存资源如内存空间,并将代码段、数据段、堆、栈等加载到内存中
- 将PCB/TCB插入就绪队列中
2)阻塞状态
当运行状态中的进程出现某些系统调用时,如I/O操作,会进入阻塞状态,等待事件的发生
- 找对应的PCB/TCB,将其从就绪队列中移除
- 经历运行状态--->保护现场--->阻塞状态的过程
- 将PCB/TCB插入阻塞队列中
3)从阻塞状态唤醒到就绪状态
当阻塞状态的进程等待的事件发生后,会进入就绪状态(信号触发)
- 查找PCB/TCB,将其从阻塞队列中移除
- 将其插入就绪队列中等待调度
4)终止状态
- 查找PCB
- 从运行状态停止,也就是归还CPU
- 子进程变成孤儿进程交给init 1号进程接管
- 归还资源给操作系统
- 从PCB/TCB队列中移除
3.1.4 CPU调度算法
调度关系着CPU的利用率和响应时间,当进程/线程进入运行状态就是占用了CPU,而什么时候占用就与调度算法有很大关系了
什么时候触发调度?
总的来说,在上面那张状态图中,跟运行状态相关联的就绪状态、阻塞状态、终止状态的出现都会触发调度
- 时间片用完:出现就绪态---运行态的转换
- 发生阻塞:当出现阻塞事件时,正在运行的进程会进入阻塞状态,此时会触发调度重新选一个进程执行
- 进程终止
调度算法
调度算法是为了提高CPU的利用率和响应时间,调度算法有抢占式和非抢占式之分:
- 非抢占式:进程一旦进入运行状态,就一直运行,直到进程终止或阻塞,才会调度其他进程
- 抢占式:进程在运行状态时,会根据时间片或优先级等因素,被其他进程抢占,从而调度其他进程(到时就换)
常见的调度算法有:
- 先来先服务(FCFS):按照进程到达的先后顺序进行调度
- 每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择第一个进程接着运行。
- 短作业优先(SJF):按照进程的运行时间进行入队列
- 每次从就绪队列选择运行时间最短的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择运行时间最短的进程接着运行。
- 时间片轮转(RR):按照时间片进行调度
- 按照公平原则,每个进程都有一个时间片,当时间片用完后,会重新进入就绪队列,等待下一次调度
- 优先级调度:按照优先级进行调度
- 每次从就绪队列选择优先级最高的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择优先级最高的进程接着运行。
- 多级反馈队列调度:结合时间片轮转和优先级调度的调度算法
- 将就绪队列分为多个队列,每个队列有一个时间片,优先级逐渐降低,当一个进程时间片用完后,会进入下一个队列等待调度
3.2 上下文切换
当CPU出现调度,需要切换到其他进程时,会涉及到上下文切换,需要经过当前进程的保存现场和下一个进程的加载恢复现场
在切换前程序会先停止运行,然后触发中断保护现场,之后操作系统会将寄存器信息压栈到PCB+内核栈中
现代操作系统都是直接调度线程,而不是进程,因为线程的切换比进程的切换要快
- 线程的上下文切换只需要切换栈和寄存器即可
- 进程的上下文切换需要切换页表、切换内存空间等操作
3.2.1 触发上下文切换的场景
当出现CPU当前运行状态的进程/线程需要转换为另一个进程/线程的场景时(也就是发生调度),就会触发上下文切换,主要有以下几种情况:
- 运行状态<--->就绪状态
- 时间片用完,剥夺CPU,通过时间中断实现切换
- 运行状态<--->挂起状态
- 资源不足挂起
- sleep主动挂起
- 运行状态<--->阻塞状态
- 硬件中断:如I/O操作等
3.2.2 线程和进程上下文切换比较
要比较两者的上下文切换区别,首先要分别了解进程和线程的上下文切换具体切换了什么内容?
1)上下文指什么?
上下文可以分为用户上下文、系统上下文和硬件上下文:
- 用户上下文:用户态的地址空间(用户空间)、页表等信息
- 系统上下文:PCB+内核栈等信息
- 硬件上下文:寄存器、程序计数器等信息
2)进程、线程、协程上下文切换的内容
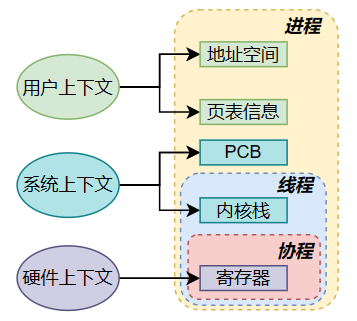
3.2.3 上下文切换的过程
进程状态的切换会触发进程的上下文切换,而切换是由中断驱动实现的
以进程为例,首先要了解进程的组成,进程的切换中保护线程就是围绕进程的组成来进行的:
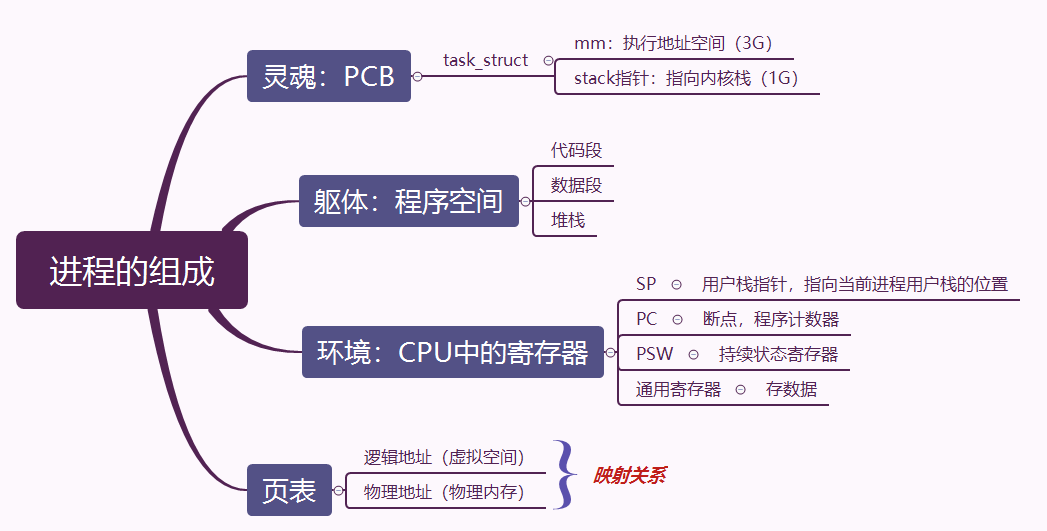
具体过程主要为
- 硬件中断:CPU收到中断信号后,会暂停当前进程的执行
- 保存当前进程的上下文:先将SP、PC保存至内核栈中
- 切换到内核态:程序计数器PC重新指向内核态的中断处理程序
- 中断处理程序:执行中断处理程序,将通用寄存器保存下来
- 调度新进程:根据调度算法选择新的进程,将其PCB、内核栈中的寄存器信息恢复到CPU中

参考资料:
3.3 协程
相比于进程和线程,协程是一种用户态的轻量级线程**
协程 VS 线程
协程的切换是用户态的切换,由内核态调度的(纯软实现),而线程需要频繁转换用户态<--->内核态,因此协程的切换速度比线程的切换速度更快
相比于线程上下文切换需要内核态+寄存器,协程的上下文内容只有硬件上下文,也就是寄存器(SP、PC、DX)的内容
进程 VS 线程 VS 协程
| 进程 | 线程 | 协程 | |
|---|---|---|---|
| 切换内容 | 用户态(页表)+内核态+硬件上下文 | 用户态+内核态+硬件上下文 | 硬件上下文 |
| 切换位置 | 内核态 | 内核态 | 用户态 |
| 切换速度 | 低 | 中 | 高 |
协程的实现
协程属于用户态的线程,因此其实现是在用户态的堆中malloc出来的栈空间,并在用户态中进行切换,切换时只需要保存寄存器的信息即可
根据堆中开辟空间的方式,有栈协程可以分为独立栈和共享栈两种:
- 独立栈:每个协程都有自己的栈空间
- 优点:切换时只需要切换栈指针即可,无需再次拷贝,因此比较快
- 缺点:独占内存资源,栈空间较大时会占用较多内存
- 共享栈:所有协程共享一个栈空间
- 优点:节省内存资源
- 缺点:切换时需要拷贝栈空间,因此切换速度较慢
在堆区中,协程的空间通过esp和ebp来控制
- esp表示栈顶
- ebp表示栈底
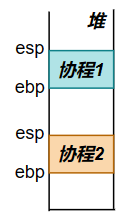
3.4 进程间通信
进程间通信主要有管道、消息队列、共享内存、信号量、信号、套接字等方式
3.4.1 管道Pipe
管道是一种半双工的通信方式,由读端和写端组成的单向通信方式
我们最常见的Linux中的指令|其实就代表了管道的使用,如ps aux | grep mysql
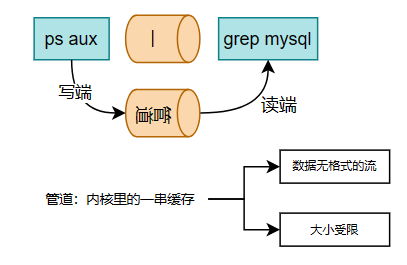
管道可以分为匿名管道和有名管道:
- 匿名管道:无文件实体,只能用于父子进程或兄弟进程之间的通信
- 有名管道:存在文件实体,可以用于任意进程之间的通信
1)存储方式
- 管道属于内核里的一块缓冲区
- 数据无格式
- 读端读取数据后,缓冲区中的数据就会被清空
- 大小有限,满了会阻塞写端,空了会阻塞读端
2)缺点
通信效率低,不适合大量数据、频繁通信的场景
3.4.2 消息队列MQ
1)存储方式
- 消息队列是以消息链表的形式存储的
- 消息队列中的消息是有格式的,可以是结构体等
- 有固定大小的存储块
2)优点
- 适用于频繁的数据交流
3)缺点
- 通信不及时:消息队列是异步的,发送和接收消息的时间不一定是同步的
- 存储块有限,不适合大量数据的通信
- 存在用户态和内核态的数据拷贝开销:发送和接收消息时,需要数据拷贝,效率较低
3.4.3 共享内存
1)存储方式
通过拿出一块虚拟内存,然后映射到物理内存中,实现共享内存的通信
2)优点
通过映射的方式不需要数据拷贝,效率较高
3.4.4 信号量
信号量只是一个计数值,通常用于进程or线程的数据同步、防止多进程竞争共享资源
信号量有两个关键操作(P&V操作):
- P操作:请求资源,对应C++的.wait()
- 信号量减1
sem<0:阻塞,表示无资源可用sem>0:继续执行
- V操作:释放资源,对应C++中的.signal()
- 信号量加1
sem<=0:唤醒一个等待的进程
3.5 其它进程类型
进程有多种类型,主要有孤儿进程、僵尸进程、守护进程等,通过Linux的ps命令可以查看,进程间通过pid号来区分
3.5.1 孤儿进程:无害(会自动回收)
孤儿进程是指父进程退出后,子进程还在运行
此时子进程的父进程会被进程号为1的init进程接管,操作系统会定期清理孤儿进程
3.5.2 僵尸进程:有危害
进程exit()退出内核后会释放该进程的所有资源(打开的文件、占用内存等),但是不会主动回收该进程的PCB,也就是该进程号还一直被占用
僵尸进程是指一个子进程已经exit(),但是父进程还没有回收它的PCB,导致子进程的PCB一直保存在内核中,这种进程就是僵尸进程
僵尸进程会占用系统资源(进程号有限),因此需要回收它,回收有两种方式:
- 父进程主动回收
- 子进程退出时发送SIGCHLD信号给父进程,父进程通过wait()或waitpid()方法回收子进程
- Kill父进程:向父进程对应的pid发送SIGKILL(9),
kil -9 ppid- 当父进程退出时,子进程会变为孤儿进程,被init进程接管并定期清理
3.5.3 守护进程
守护进程是一种在挂在后台运行的进程,通常用于系统服务的启动和管理
它会定期执行一些系统任务,如日志清理、定时任务等;其父进程是init进程,因此不会成为僵尸进程,同时操作系统结束它才会结束
3.6 多线程同步问题
多线程之间会存在资源竞争的问题,因此有互斥和同步的问题
- 互斥:某段代码同一时间只能被一个线程访问,其它线程需要阻塞等待进入
- 同步:多个线程之间的数据互通需要协调工作,如生产者-消费者模型、读写锁等
3.6.1 为什么多线程需要同步?
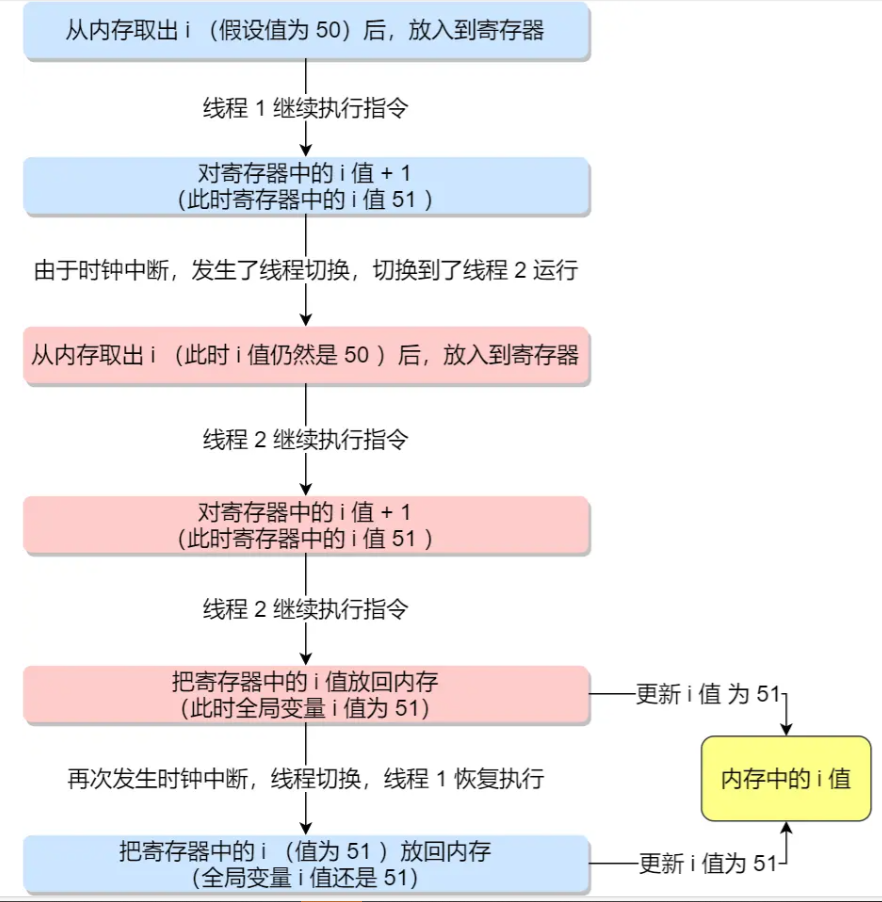
假设有多线程共享的变量i,当执行i=i+1时,实际上在汇编层面上不是一个原子操作,而是分为读取、计算、写入三个步骤:
- 读取:内存中
i的值-->寄存器中 - 计算:寄存器中的值+1
- 写入:寄存器中的值-->内存中
i
因此多线程很有可能在其中某个步骤被抢占,导致数据不一致的问题
在文章从0开始实现线程池(C++)中有介绍互斥锁解决多线程数据共享问题以及死锁问题的代码模拟,这里不再赘述
3.6.2 实现同步的方式
实现同步有加锁和不加锁两种方式:
- 不加锁:通过原子操作来保证数据的一致性,如CAS、TAS等
- 加锁:通过互斥锁、读写锁、条件变量等方式来保证数据的一致性
也可以将锁分为乐观锁(通常也是无锁编程)和悲观锁:
- 乐观锁:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作
- 重写成本高,不适合冲突频繁场景
- 通常加入版本号/时间戳等字段作为乐观锁的判断依据
- 悲观锁:认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁
- 适合冲突频繁场景
- 锁住等待的成本高
各种锁如下所示:

3.6.3 死锁问题
在文章从0开始实现线程池(C++)中有介绍互斥锁解决多线程数据共享问题以及死锁问题的代码模拟,这里不再赘述