一、两种日志系统类型
1.1 同步日志系统
同步日志系统是指日志写入和日志输出是同步的,即写入日志后,立即输出到日志文件中。(本项目中配置文件默认为同步日志)
由于同步日志中日志写入函数跟工作函数是串行的,所以涉及到文件IO操作,如果单条日志内容较大时,会导致工作函数阻塞,影响工作效率。
1.2 异步日志系统
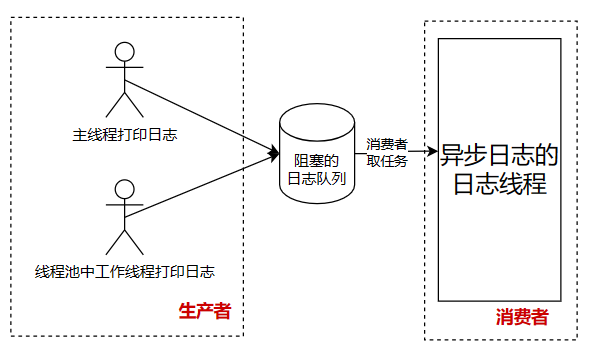
异步日志系统是指日志写入和日志输出是异步的,即写入日志后,不立即输出到日志文件中,而是先写入到一个队列 中,然后由另一个线程(日志线程)负责将缓冲区中的日志内容输出到日志文件中。也就是说工作线程和日志线程是并行的,工作线程作为生产者 只负责将日志信息传到队列 中就结束了,剩下的操作交由日志线程作为消费者 全权处理。
由于异步日志中单独开辟了一个线程来处理日志输出,所以这里需要有一些关于线程的基础知识,比如线程的创建、线程的同步(互斥锁&条件变量)、线程的销毁等。具体这部分基础知识可以先学习本人的另一篇博客:从0开始实现线程池(C++) 。
在上面推荐的博客中,我们了解到生产者-消费者模型,异步日志系统就是一个典型的生产者-消费者模型。
生产者 :主线程 &&
线程池中的工作线程,将日志信息写入到队列中消费者 :日志线程,从队列中取出日志信息,输出到日志文件中
二、单例模式
单例模式是一种常见的设计模式,它保证单例类只有一个实例 ,并提供一个全局访问点。
实现思路:
私有化 它的构造函数 ,以防止外界创建单例类的对象;使用类的私有静态指针变量 指向类的唯一实例,并用一个公有的静态方法获取该实例。
实现单例模式有两种方式:
饿汉模式 :迫不及待地,在程序启动或单例类被加载的时候就创建单例对象;
懒汉模式 :懒得理你,只有在第一次调用获取单例对象的方法时才创建单例对象;
由于多线程中可能会有多个线程同时第一次 调用获取单例对象的方法,所以在首次调用中需要确保线程安全
实现线程安全:加锁 、双重检查锁 。
关于单例模式的详细内容,可以参考本人的另一篇博客:设计模式1:单例模式(C++) 。
在单例模式的博客中,我们需要重点关注C++11后,局部静态变量可以实现无锁保证线性安全,所以在实现日志系统时,我们可以使用局部静态变量来实现单例模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 class Log {public : static Log *get_instance () static Log instance; return &instance; } private : Log (); virtual ~Log (); };
三、阻塞队列
如果选择异步日志系统 ,那么就需要使用阻塞队列 来实现生产者-消费者模型。
对于生产者 来说,写日志到队列中如果队列已经满了,那么直接返回写入失败,不会阻塞(因为生产者是主线程和线程池中的工作线程,不能阻塞,队列满时写入日志就会丢失一条日志,所以队列尽可能设置大一点)
但是对于消费者 来说,如果队列为空,那么消费者线程就会阻塞,直到队列中有新的数据再继续消费(也就是说队列执行pop操作时,如果队列为空,日志线程就会一直阻塞在pop操作)
所以我们实现阻塞队列的思想就是:
消费者 读取队列pop操作:如果队列为空,就一直阻塞,直到队列中有新的数据再继续消费生产者 写入队列push操作(失败):如果队列满了,直接返回写入失败生产者 写入队列push操作(成功):如果队列不为空,就唤醒消费者线程(日志线程),日志线程会结束pop阻塞,从队列中取出日志信息,输出到日志文件中
在实现阻塞队列时,我们需要考虑线程安全问题,所以需要使用互斥锁 和条件变量 来保证线程安全。
我们前面已经在线程池 的设计中封装了互斥锁 和条件变量 ,所以可以直接使用封装后的locker。
在C++中,阻塞队列可以很方便地使用std::queue来实现,在本项目中,我们尝试通过循环数组 来模拟实现一个阻塞队列 (先进先出)。
1 2 m_back = (m_back + 1 ) % m_max_size; m_front = (m_front + 1 ) % m_max_size;
循环数组的概念使我们在push时其实是向右循环移动队尾指针 并覆盖这个位置上原有的数据;在pop时其实是向右循环移动队首指针 并覆盖这个位置上原有的数据。(先进先出)
阻塞队列的实现主要包含入队push 、出队pop 、清空clear 三个操作,以及队列是否为空 和队列是否已满 的判断。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 #ifndef BLOCK_QUEUE_H #define BLOCK_QUEUE_H #include <iostream> #include <stdlib.h> #include <pthread.h> #include <sys/time.h> #include "../lock/locker.h" using namespace std;template <class T >class block_queue {public : block_queue (int max_size = 1000 ){ if (max_size <= 0 )exit (-1 ); m_max_size = max_size; m_array = new T[m_max_size]; m_size = 0 ; m_front = -1 ; m_back = -1 ; } void clear () m_mutex.lock (); m_size = 0 ; m_front = -1 ; m_back = -1 ; m_mutex.unlock (); } ~block_queue (){ m_mutex.lock (); if (m_array != nullptr ){ delete [] m_array; } m_mutex.unlock (); } bool full () m_mutex.lock (); if (m_size >= m_max_size){ m_mutex.unlock (); return true ; } m_mutex.unlock (); return false ; } bool empty () m_mutex.lock (); if (m_size == 0 ){ m_mutex.unlock (); return true ; } m_mutex.unlock (); return false ; } bool front (T &value) m_mutex.lock (); if (m_size == 0 ){ m_mutex.unlock (); return false ; } value = m_array[m_front]; m_mutex.unlock (); return true ; } bool back (T &value) m_mutex.lock (); if (m_size == 0 ){ m_mutex.unlock (); return false ; } value = m_array[m_back]; m_mutex.unlock (); return true ; } int size () int tmpSize = 0 ; m_mutex.lock (); tmpSize = m_size; m_mutex.unlock (); return tmpSize; } int max_size () int tmpMaxSize = 0 ; m_mutex.lock (); tmpMaxSize = m_max_size; m_mutex.unlock (); return tmpMaxSize; } bool push (const T &item) m_mutex.lock (); if (m_size >= m_max_size){ m_cond.broadcast (); m_mutex.unlock (); return false ; } m_back = (m_back + 1 ) % m_max_size; m_array[m_back] = item; m_size++; m_cond.broadcast (); m_mutex.unlock (); return true ; } bool pop (T &item) m_mutex.lock (); while (m_size <= 0 ){ if (!m_cond.wait (m_mutex.get ())){ m_mutex.unlock (); return false ; } } m_front = (m_front + 1 ) % m_max_size; item = m_array[m_front]; m_size--; m_mutex.unlock (); return true ; } bool pop (T &item, int ms_timeout) struct timespec t =0 ,0 }; struct timeval now =0 ,0 }; gettimeofday (&now, NULL ); m_mutex.lock (); if (m_size <= 0 ){ t.tv_sec = now.tv_sec + ms_timeout / 1000 ; t.tv_nsec = (ms_timeout % 1000 ) * 1000 ; if (!(m_cond.timewait (m_mutex.get (), t))){ m_mutex.unlock (); return false ; } } if (m_size <= 0 ){ m_mutex.unlock (); return false ; } m_front = (m_front + 1 ) % m_max_size; item = m_array[m_front]; m_size--; m_mutex.unlock (); return true ; } private : locker m_mutex; cond m_cond; T *m_array; int m_size; int m_max_size; int m_front; int m_back; }; #endif
其中重点关注pop操作,当判断队列满时,在pop()函数中会调用m_cond.wait(m_mutex.get())函数使日志线程阻塞在当前的pop函数中,等待生产者线程往队列中成功push数据从而唤醒消费者线程(生产者添加数据后,通过m_cond.broadcast()唤醒消费者线程)。
四、日志读写的基础API
4.1 fputs函数
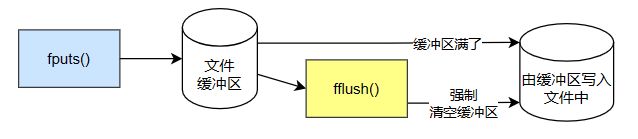
fputs函数是C/C++的一个标准库函数,用于将字符串写入到指定的文件流中。对于打开的文件流,fputs函数会将字符串写入到文件流的当前位置,然后将文件流的当前位置后移,以便下次写入。
1 int fputs (const char *str, FILE *stream)
str:要写入的字符串(经过自定义格式化处理的日志信息)
stream:文件流指针(日志文件指针)
4.2 fflush函数
fflush函数是C/C++的一个标准库函数,用于刷新流的缓冲区。对于输出流,fflush函数会将缓冲区的内容立即写入到文件中。
fputs函数写入文件时,会先写入到缓冲区,当缓冲区满了或者调用fflush函数时,才会将缓冲区的内容写入到文件中。所以为了避免日志信息丢失,需要在每次写入日志后调用fflush函数,强制将缓冲区的内容写入到文件中。
1 int fflush (FILE *stream)
五、日志类实现(同步+异步)
5.1 日志类的初始化
日志类的初始化可以分为同步初始化和异步初始化,同步和异步的判断由传入的阻塞队列大小 决定。
同步初始化 :阻塞队列大小为0 异步初始化 :阻塞队列大小大于0
日志初始化的内容为:
初始化日志方式(同步/异步),异步初始化需要创建日志线程 以及阻塞队列
初始化日志文件路径、日志文件名、日志最大行数、日志缓冲区大小
根据解析的日志文件路径和日志文件名,创建/打开 日志文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 bool Log::init (const char *file_name, int close_log, int log_buf_size, int split_lines, int max_queue_size) if (max_queue_size >= 1 ){ m_is_async = true ; m_log_queue = new block_queue<string>(max_queue_size); pthread_t tid; pthread_create (&tid, NULL , flush_log_thread, NULL ); } m_close_log = close_log; m_log_buf_size = log_buf_size; m_buf = new char [m_log_buf_size]; memset (m_buf, '\0' , m_log_buf_size); m_split_lines = split_lines; time_t t = time (NULL ); struct tm *sys_tm =localtime (&t); struct tm my_tm = const char *p = strrchr (file_name, '/' ); char log_full_name[256 ] = {0 }; if (p==NULL ){ snprintf (log_full_name, 255 , "%d_%02d_%02d_%s" , my_tm.tm_year+1900 , my_tm.tm_mon+1 , my_tm.tm_mday, file_name); }else { strcpy (log_name, p + 1 ); strncpy (dir_name, file_name, p - file_name + 1 ); snprintf (log_full_name, 255 , "%s%d_%02d_%02d_%s" , dir_name, my_tm.tm_year + 1900 , my_tm.tm_mon + 1 , my_tm.tm_mday, log_name); } m_today = my_tm.tm_mday; m_fp = fopen (log_full_name, "a" ); if (m_fp == NULL ){ return false ; } return true ; }
5.2 日志的等级
日志的等级分为INFO 、DEBUG 、WARN 、ERROR 四个等级。
INFO :普通信息,报告系统正常工作的信息,当前执行的流程和收发信息等DEBUG :调试信息,报告系统调试信息,用于调试程序,在开发和测试阶段使用WARN :警告信息,报告系统警告信息,表明一个可能的问题,不影响程序的正常运行,同样是调试开发时使用ERROR 和Fatal :错误信息,报告系统错误信息,表明一个严重的问题,程序可能无法继续运行
日志等级的设置可以通过宏定义 来实现
1 2 3 4 #define LOG_DEBUG(format, ...) if (0 == m_close_log) {Log::get_instance()->write_log(0, format, ##__VA_ARGS__); Log::get_instance()->flush();} #define LOG_INFO(format, ...) if (0 == m_close_log) {Log::get_instance()->write_log(1, format, ##__VA_ARGS__); Log::get_instance()->flush();} #define LOG_WARN(format, ...) if (0 == m_close_log) {Log::get_instance()->write_log(2, format, ##__VA_ARGS__); Log::get_instance()->flush();} #define LOG_ERROR(format, ...) if (0 == m_close_log) {Log::get_instance()->write_log(3, format, ##__VA_ARGS__); Log::get_instance()->flush();}
在生产者通过宏定义调用日志写入函数时,需要传入日志等级 、日志内容format 、可变参数 。调用宏定义日志函数后,依此执行write_log函数实现写入(同步直接fputs写入,异步push进阻塞队列)和flush函数。
其中日志内容format 和可变参数 使用vsnprintf函数实现格式化解析输出
5.3 日志的写入write_log函数
日志类中通过write_log函数实现对生产者传入的日志等级、日志内容 进行格式化解析和封装。
5.3.1
可变参数的格式化解析vsnprintf函数
c++中的可变参数格式化解析可以使用vsnprintf函数实现
vsnprintf函数原型:
1 int vsnprintf (char *str, size_t size, const char *format, va_list ap)
str:存储格式化后的字符串(日志主体内容)
size:存储格式化后的字符串的大小(手动分配的)
format:格式化字符串(日志内容),类似printf函数的格式化字符串
ap:可变参数列表
如LOG_INFO("%s%d", "listen the port ", m_port);中的"%s%d"代表format,"listen the port "和m_port是可变参数
5.3.2 日志内容格式化输出
本项目中的日志按照日期 时间 日志等级
日志内容 的格式输出,同时日志文件具有行数限制 和按天分文件 的特性。因此在写入日志前:
需要判断当前日期是否改变
如果日期改变,需要关闭当前日志文件,重新根据当前日期创建新的日志文件
需要判断当前日志行数是否达到上限
如果日志行数达到上限,需要关闭当前日志文件,在当前日期的文件名基础上加上行数后缀,重新创建新的日志文件
完成格式化内容处理后,再根据同步/异步 的不同,进行日志内容的写入操作。从这里也可以看出,异步日志 中,添加到阻塞队列 中的日志内容是格式化后的字符串 ,所以在日志线程中取出后直接调用fputs()写入到日志文件中即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 void Log::write_log (int level, const char *format, ...) char s[16 ] = {0 }; switch case 0 : strcpy (s, "[debug]:" ); break ; case 1 : strcpy (s, "[info]:" ); break ; case 2 : strcpy (s, "[warn]:" ); break ; case 3 : strcpy (s, "[erro]:" ); break ; default : strcpy (s, "[info]:" ); break ; } struct timeval now =0 , 0 }; gettimeofday (&now, NULL ); time_t t = now.tv_sec; struct tm *sys_tm =localtime (&t); struct tm my_tm = m_mutex.lock (); m_count++; if (m_today != my_tm.tm_mday || m_count % m_split_lines == 0 ) { char new_log[256 ] = {0 }; fflush (m_fp); fclose (m_fp); char tail[16 ] = {0 }; snprintf (tail, 16 , "%d_%02d_%02d_" , my_tm.tm_year + 1900 , my_tm.tm_mon + 1 , my_tm.tm_mday); if (m_today != my_tm.tm_mday) { snprintf (new_log, 255 , "%s%s%s" , dir_name, tail, log_name); m_today = my_tm.tm_mday; m_count = 0 ; } else { snprintf (new_log, 255 , "%s%s%s.%lld" , dir_name, tail, log_name, m_count / m_split_lines); } m_fp = fopen (new_log, "a" ); } m_mutex.unlock (); va_list valst; va_start (valst, format); string log_str; m_mutex.lock (); int n = snprintf (m_buf, 48 , "%d-%02d-%02d %02d:%02d:%02d.%06ld %s " , my_tm.tm_year + 1900 , my_tm.tm_mon + 1 , my_tm.tm_mday, my_tm.tm_hour, my_tm.tm_min, my_tm.tm_sec, now.tv_usec, s); int m = vsnprintf (m_buf + n, m_log_buf_size - n - 1 , format, valst); m_buf[n + m] = '\n' ; m_buf[n + m + 1 ] = '\0' ; log_str = m_buf; m_mutex.unlock (); if (m_is_async && !m_log_queue->full ()) { m_log_queue->push (log_str); } else { m_mutex.lock (); fputs (log_str.c_str (), m_fp); m_mutex.unlock (); } va_end (valst); }
5.4 日志的刷新flush函数
日志类中通过flush函数实现对日志文件的刷新操作,即将缓冲区的内容强制写入到文件中。保证有新的日志到达后,先将当前缓冲区的内容写入到文件中,避免日志丢失。
5.5 异步日志中线程的实现
异步日志在初始化时创建了一个日志线程 ,该线程的工作函数是flush_log_thread,主要负责从阻塞队列中取出日志消息并写入到日志文件中。
1 2 3 pthread_t tid;pthread_create (&tid, NULL , flush_log_thread, NULL );
关于flush_log_thread函数的实现
异步日志的工作线程函数flush_log_thread是一个静态函数,会调用日志类的async_write_log函数,实现从阻塞队列中取出日志消息并写入到日志文件中。
1 2 3 4 5 static void *flush_log_thread (void *args) Log::get_instance ()->async_write_log (); }
关于async_write_log函数的实现
异步日志的工作线程函数中,async_write_log会不断地从阻塞队列中取出日志消息并写入到日志文件中。根据前面实现的阻塞队列 的特性,如果队列为空,那么日志线程会阻塞在pop操作中
所以日志工作线程的while循环执行pop操作时,如果队列为空,会一直阻塞在while语句中,直到队列中生产者添加新的日志消息,唤醒日志线程,继续pop操作,并进入while循环里面的执行语句中
此时获得的日志字符串已经是格式化过的了(阻塞队列中的消息全是格式化后再由生产者push进去的),所以直接调用fputs函数写入到日志文件中即可。
当阻塞队列中的日志消息全部写入到日志文件中后,日志线程会继续阻塞在pop操作中,等待生产者线程继续往队列中push新的日志消息。
1 2 3 4 5 6 7 8 9 10 void *async_write_log () string single_log; while (m_log_queue->pop (single_log)){ m_mutex.lock (); fputs (single_log.c_str (), m_fp); m_mutex.unlock (); } }
六、总结
至此我们已经完成了一个通用的日志系统的设计和实现,包含了同步日志 和异步日志 两种方式。相当于造了个轮子,以后可以直接拿来使用。
本文关键的知识点为线程安全 、生产者-消费者模型 、单例模式 、阻塞队列 、日志格式化解析和封装 等。
到目前为止,WebServer的功能基本实现了,通过Makefile文件执行make命令编译生成可执行文件server,通过./server命令运行服务器,即可在浏览器中访问http://localhost:9006查看效果。同时完整项目在GitHub 上。
在WebServer项目的实现中,我们最后还需要通过Web性能压测工具WebBench对服务器进行压力测试,以验证服务器的性能和稳定性。具体压测的内容和结果可以参考本人的另一篇博客:WebServer项目实战9:WebBench压力测试 。