一、从HTTP用户类在主线程epoll监听中的初始化说起
1.1
WebServer.cpp文件中的HTTP用户初始化
回到WebServer.cpp类中的eventLoop函数,我们可以看到在epoll监听的主线程中,当处理新的客户端连接事件 时,会在处理新连接的dealclientdata函数中,通过timer函数同时初始化一个http
user 和一个定时器。
1.2
http_conn.cpp文件中的HTTP用户初始化函数的实现
在http_conn.cpp文件中对新用户连接的初始化
包括类中一些如数据库信息、数据读取模式等变量、以及一些HTTP处理中间变量的初始化
同时还包括对主函数中的epoll监听该客户端socketfd的初始化
对http_conn类中的变量初始化
这里的初始化包括传参的init函数和无参重载的init函数,其中传参的init函数主要是对客户端连接信息的初始化,而无参重载的init函数主要是对类中功能实现的一些中间变量的初始化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void http_conn::init (int sockfd, const sockaddr_in &addr, char *root, int TRIGMode, int close_log, string user, string passwd, string sqlname) m_sockfd = sockfd; m_address = addr; addfd (m_epollfd, sockfd, true , m_TRIGMode); m_user_count++; doc_root = root; m_TRIGMode = TRTGMide; m_close_log = close_log; strcpy (sql_user, user.c_str ()); strcpy (sql_passwd, passwd.c_str ()); strcpy (sql_name, sqlname.c_str ()); init (); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void http_conn::init () mysql = NULL ; bytes_to_send = 0 ; bytes_have_send = 0 ; m_check_state = CHECK_STATE_REQUESTLINE; m_linger = false ; m_method = GET; m_url = 0 ; m_version = 0 ; m_content_length = 0 ; m_host = 0 ; m_start_line = 0 ; m_checked_idx = 0 ; m_read_idx = 0 ; m_write_idx = 0 ; cgi = 0 ; m_state = 0 ; timer_flag = 0 ; improv = 0 ; memset (m_read_buf, '\0' , READ_BUFFER_SIZE); memset (m_write_buf, '\0' , WRITE_BUFFER_SIZE); memset (m_real_file, '\0' , FILENAME_LEN); }
对主函数中的epoll监听该客户端socketfd的初始化
我们看到传参的init函数还执行了addfd函数,这个函数就是处理主线程中epoll监听的socketfd的初始化
这里涉及的几个epoll相关函数其实跟之前在timer类中的几个相关函数是一样的代码 ,只是为了区分epoll中对serverfd的初始化监听和对clientfd的初始化监听,所以这里将这几个函数又单独封装在了http_conn类中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void addfd (int epollfd, int fd, bool one_shot, int TRIGMode) epoll_event event; event.data.fd = fd; if (TRIGMode == 1 ) event.events = EPOLLIN | EPOLLET | EPOLLRDHUP; else event.events = EPOLLIN | EPOLLRDHUP; if (one_shot) event.events |= EPOLLONESHOT; epoll_ctl (epollfd, EPOLL_CTL_ADD, fd, &event); setnonblocking (fd); }
1 2 3 4 5 6 7 8 int setnonblocking (int fd) int old_option = fcntl (fd, F_GETFL); int new_option = old_option | O_NONBLOCK; fcntl (fd, F_SETFL, new_option); return old_option; }
二、通过Reactor和Proactor两种事件处理模式理解HTTP的读事件处理
1.
read_once()函数处理socketfd的读事件
根据上一节的学习,我们已经知道,Reactor模式会在工作线程 worker中取出任务并执行read_once()
而Proactor模式会在主线程 epoll监听到客户端socketfd读事件后,直接在主线程执行read_once()
那么这个read_once()函数到底为何方神圣?
read_once()函数封装在http_conn类中,实现了epoll两种触发模式的读事件。
LT模式
LT模式下不需要一次性读取完,会分多次读取,所以每次读的时候用if执行就行,不需要循环执行recv函数
ET模式
ET模式下需要一次性读取完,所以需要while执行recv函数,直到读完为止
最终读取的数据都会存放在当前用户实例化http_conn类的m_read_buf中,然后用m_read_idx变量标记读取的数据的长度(m_read_idx个bytes)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 bool http_conn::read_once () if (m_read_idx >= READ_BUFFER_SIZE) { return false ; } int bytes_read = 0 ; if (m_TRIGMode == 0 ){ bytes_read = recv (m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0 ); m_read_idx += bytes_read; if (bytes_read <= 0 ){ return false ; } return true ; } else { while (true ){ bytes_read = recv (m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0 ); if (bytes_read == -1 ){ if (errno == EAGAIN || errno == EWOULDBLOCK) break ; return false ; }else if (bytes_read == 0 ){ return false ; } m_read_idx += bytes_read; } return true ; } }
2.
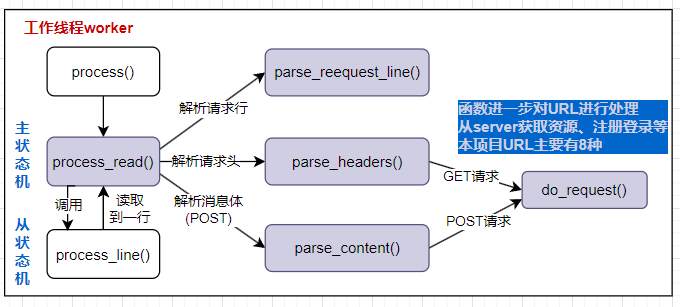
process()函数进行报文解析和处理
process()函数同样封装在http_conn类中
无论是Reactor模式还是Proactor模式,process()函数都是在工作线程中执行的,它的作用是对read_once()函数读取到的报文进行解析和处理。
Reactor模式下是工作线程 中取出任务并执行socket读操作(read_once())后再执行process()函数进行报文解析和处理。
而Proactor模式下工作线程 直接执行process()函数进行报文解析和处理。(因为主线程已经完成了read_once()的操作)
process()函数主要先处理客户端的请求报文 ,如果请求报文还没有读完,那么就继续将clientfd注册为可读事件 ,等待下一次读取。成功解析处理完请求报文后,根据请求报文打包响应报文 ,然后将clientfd注册为可写事件 ,等待下一次写入。
所以process()函数除了涉及报文的处理外,还需要涉及到epoll 的重置事件监听模式 和删除描述符 操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void http_conn::process () HTTP_CODE read_ret = process_read (); if (read_ret == NO_REQUEST) { modfd (m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode); return ; } bool write_ret = process_write (read_ret); if (!write_ret) { close_conn (); } modfd (m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode); }
epoll重置事件监听模式和删除描述符与关闭客户端连接操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 void modfd (int epollfd, int fd, int ev, int TRIGMode) epoll_event event; event.data.fd = fd; if (1 == TRIGMode) event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP; else event.events = ev | EPOLLONESHOT | EPOLLRDHUP; epoll_ctl (epollfd, EPOLL_CTL_MOD, fd, &event); } void removefd (int epollfd, int fd) epoll_ctl (epollfd, EPOLL_CTL_DEL, fd, 0 ); close (fd); } int http_conn::m_user_count = 0 ;int http_conn::m_epollfd = -1 ;void http_conn::close_conn (bool real_close) if (real_close && (m_sockfd != -1 )){ printf ("close %d\n" , m_sockfd); removefd (m_epollfd, m_sockfd); m_sockfd = -1 ; m_user_count--; } }
三、HTTP报文的主从状态机解析模式
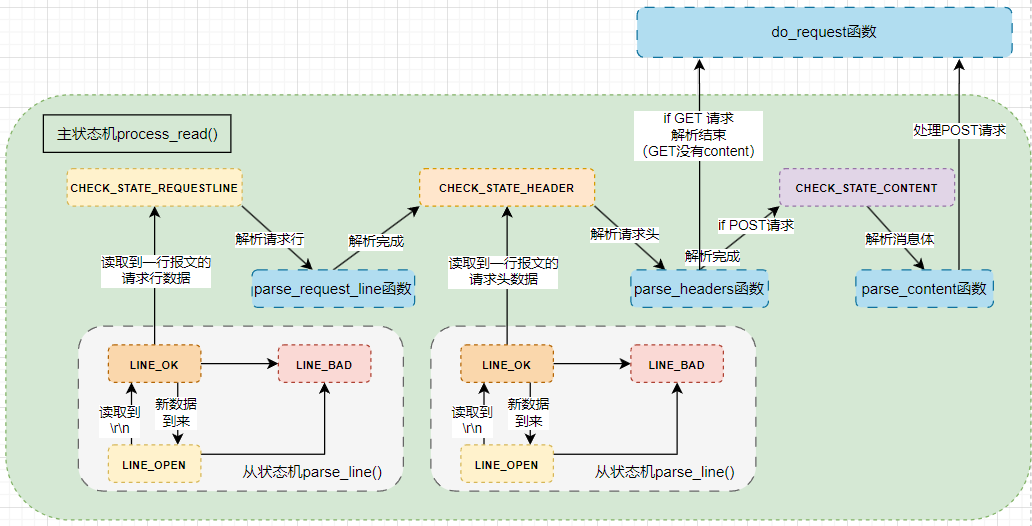
3.1 主从状态机模式
从状态机 主要是将read_once读取到的数据通过识别到的\r\n结束符进行分割,取出一行数据交给主状态机 进行处理。
状态机的实现过程如下图所示:
从状态机 有三种状态表示读取一行的状态
LINE_OK:读取到一个完整的行LINE_BAD:行读取出错(缺少\r或\n)LINE_OPEN:行数据尚且不完整,如LT模式下还需要继续不断读取 主状态机 有三种状态表示解析报文的状态
CHECK_STATE_REQUESTLINE:解析请求行(init初始化一个客户user时就会默认初始化为这个状态)CHECK_STATE_HEADER:解析头部字段CHECK_STATE_CONTENT:解析请求内容(POST有消息体,GET无)
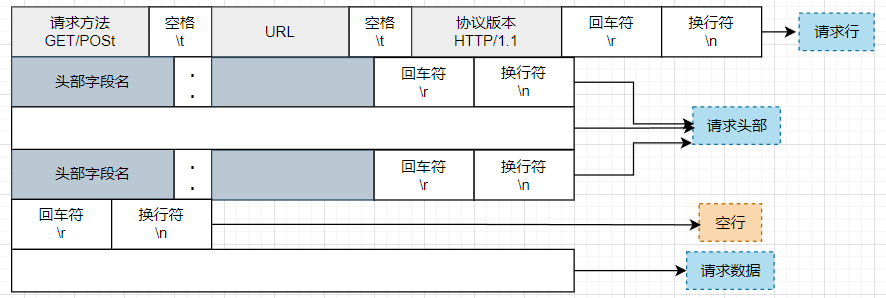
3.2 HTTP报文格式
HTTP报文格式中的请求行、请求头、请求数据(消息主体) 分别对应了主状态机 中的三种解析状态 。
3.3 从状态机的实现逻辑
从状态机的实现逻辑主要是通过http_conn类中的parse_line函数实现的,这个函数的作用是通过识别到的\r\n作为一行数据的结束符进行分割,取出一行数据交给主状态机 进行处理。
多一个LINE_OPEN状态是因为在LT模式下,需要不断读取数据,直到读取到一个完整的行。(也就是当前处理的buffer有可能不是完整的,需要持续解析)
具体实现逻辑细节可以看代码注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 http_conn::LINE_STATUS http_conn::parse_line () char temp; for (;m_checked_idx < m_read_idx; ++m_checked_idx){ temp = m_read_buf[m_checked_idx]; if (temp == '\r' ){ if ((m_checked_idx + 1 ) == m_read_idx){ return LINE_OPEN; } else if (m_read_buf[m_checked_idx + 1 ] == '\n' ){ m_read_buf[m_checked_idx++] = '\0' ; m_read_buf[m_checked_idx++] = '\0' ; return LINE_OK; } return LINE_BAD; } else if (temp == '\n' ){ if (m_checked_idx > 1 && m_read_buf[m_checked_idx - 1 ] == '\r' ){ m_read_buf[m_checked_idx - 1 ] = '\0' ; m_read_buf[m_checked_idx++] = '\0' ; return LINE_OK; } return LINE_BAD; } } return LINE_OPEN; }
3.4 主状态机的实现逻辑
主状态机的实现逻辑主要是通过http_conn类中的process_read函数实现的,这个函数的作用是对parse_line函数读取到的一行数据进行下一步处理,处理是根据从状态机的读取状态 配合主状态机的解析状态 进行的。
其中如果是单纯的GET请求,那么只需要解析请求行和请求头,而不需要解析请求内容,我们使用从状态机的((line_status = parse_line()) == LINE_OK)进行判断就行,每读完完整一行就主状态机进行一次解析(请求行or请求头)。
但是为了保证客户用户名和密码的安全,我们还需要对POST请求的请求内容进行解析,这时候我们就需要使用主状态机的m_check_state == CHECK_STATE_CONTENT进行判断,这个状态是在解析请求头的时候就已经确定了的。当主状态机状态转为CHECK_STATE_CONTENT时,此时就不需要再进入从状态机的parse_line函数进行读取了,因为消息体没有固定的行结束标志(\r\n),所以我们直接在主状态机中进行解析,根据m_read_idx读完剩下的数据就行。
同时为了主状态机处理完完整的HTTP报文后能退出while循环,我们在解析完content后将line_status重置为LINE_OPEN代表结束。(这里由于进入content解析状态前,line_status还会保持上一个状态的LINE_OK,所以不会影响主状态机进入content的解析)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 http_conn::HTTP_CODE http_conn::process_read () LINE_STATUS line_status = LINE_OK; HTTP_CODE ret = NO_REQUEST; char *text = 0 ; while ((m_check_state == CHECK_STATE_CONTENT && line_status == LINE_OK) || ((line_status = parse_line ()) == LINE_OK)){ text = get_line (); m_start_line = m_checked_idx; switch case CHECK_STATE_REQUESTLINE: { ret = parse_request_line (text); if (ret == BAD_REQUEST){ return BAD_REQUEST; } break ; } case CHECK_STATE_HEADER: { ret = parse_headers (text); if (ret == BAD_REQUEST){ return BAD_REQUEST; } else if (ret == GET_REQUEST){ return do_request (); } break ; } case CHECK_STATE_CONTENT: { ret = parse_content (text); if (ret == GET_REQUEST){ return do_request (); } line_status = LINE_OPEN; break ; } default : return INTERNAL_ERROR; } } return NO_REQUEST; }
四、主状态机三部分的解析逻辑
4.1 解析请求行
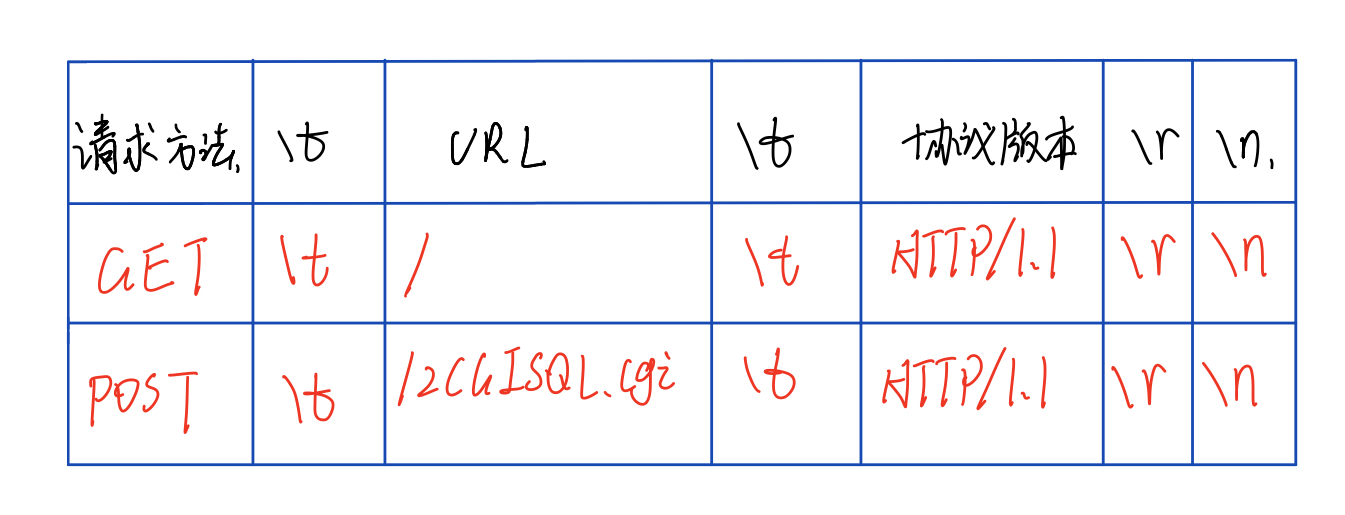
解析请求行的逻辑主要是通过http_conn类中的parse_request_line函数实现的,这个函数的作用是对请求行进行解析,解析出请求方法、请求URL、HTTP版本号。其中请求行的格式举例如下所示:
由于请求头只有一行,所以我们只需要解析一次结束后,就将主状态机的状态从CHECK_STATE_REQUESTLINE转为CHECK_STATE_HEADER。
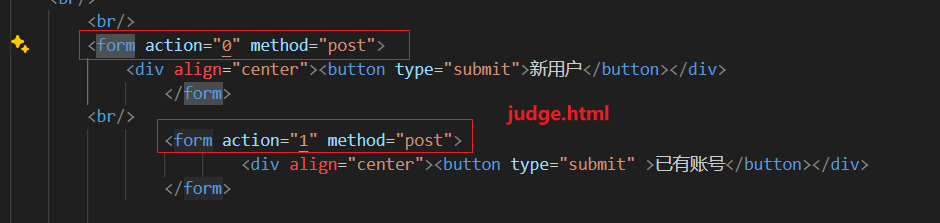
其中获取的URL在本项目中共有8种情况,分别是:
/:主页,即judge.html,(GET) /0:注册页面,即register.html,(POST) /1:登录页面,即log.html,(POST) /2CGISQL.cgi:登录检验,(POST)
成功:跳转到welcome.html
失败:跳转到logError.html(action跟log.html相同,都为2CGISQL.cgi)
/3CGISQL.cgi:注册检验,(POST)
成功:跳转到log.html
失败:跳转到registerError.html(action跟register.html相同,都为3CGISQL.cgi)
/5:跳转到picture.html图片请求页面,(POST) /6:跳转到video.html视频请求页面,(POST) /7:跳转到fans.html关注页面,(POST)
在请求头我们只对/进行处理,剩下的交给do_request函数统一进行处理和响应。(也就是只处理最开始的主界面)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 http_conn::HTTP_CODE http_conn::parse_request_line (char *text) m_url = strpbrk (text, " \t" ); if (!m_url) { return BAD_REQUEST; } *m_url++ = '\0' ; char *method = text; if (strcasecmp (method, "GET" ) == 0 ) m_method = GET; else if (strcasecmp (method, "POST" ) == 0 ) { m_method = POST; cgi = 1 ; } else return BAD_REQUEST; m_url += strspn (m_url, " \t" ); m_version = strpbrk (m_url, " \t" ); if (!m_version) return BAD_REQUEST; *m_version++ = '\0' ; m_version += strspn (m_version, " \t" ); if (strcasecmp (m_version, "HTTP/1.1" ) != 0 ) return BAD_REQUEST; if (strncasecmp (m_url, "http://" , 7 ) == 0 ) { m_url += 7 ; m_url = strchr (m_url, '/' ); } if (strncasecmp (m_url, "https://" , 8 ) == 0 ) { m_url += 8 ; m_url = strchr (m_url, '/' ); } if (!m_url || m_url[0 ] != '/' ) return BAD_REQUEST; if (strlen (m_url) == 1 ) strcat (m_url, "judge.html" ); m_check_state = CHECK_STATE_HEADER; return NO_REQUEST; }
下面我们再来讲一下HTTP是怎么实现将URL封装在报文中的。
我们知道,静态http页面实际上是通过.html文件来实现的,浏览器可以解析显示对应的html文件。我们在设计.html文件时,会通过html的form标签来实现用户表单的提交,这个表单提交的action属性就是请求行 的URL,method属性就是请求行的method(GET/POST)。
4.2 解析请求头
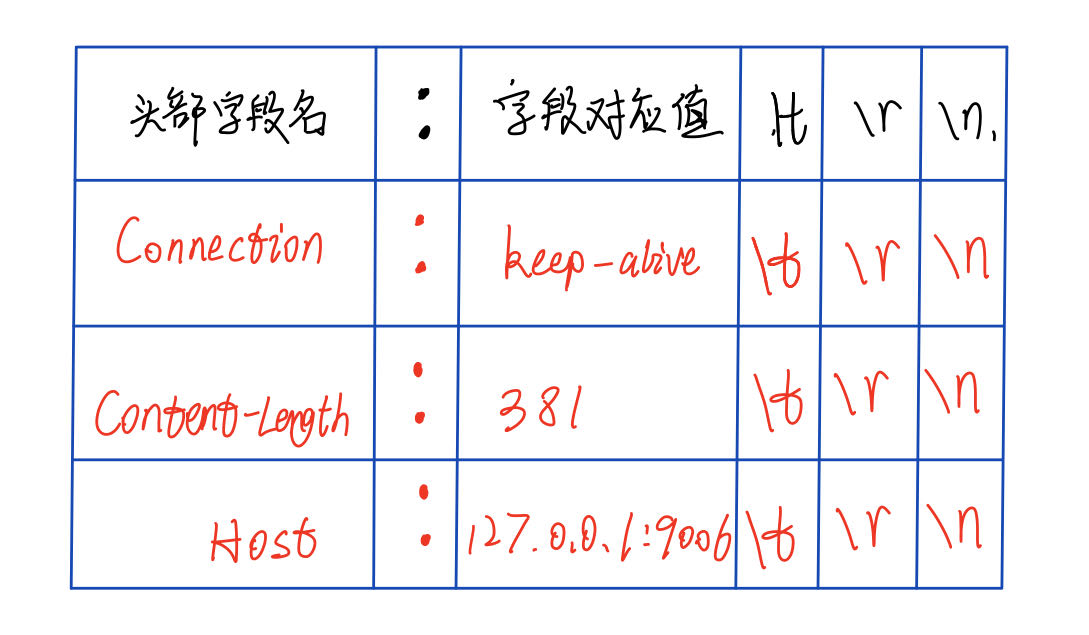
解析请求头的逻辑是通过http_conn类中的parse_headers函数实现的,这个函数的作用是对请求头进行解析,解析出请求头的字段和值 。其中请求头的格式举例如下所示:
其中本项目只对Connection、Content-Length、Host三个字段进行处理,剩下的字段直接跳过
Connection:判断是长连接还是短连接,有两个可能值keep-alive或close
HTTP/1.1默认是长连接,所以一般收到的都是keep-alive
Content-Length:请求内容的长度,用于判断主状态机是否需要转移到消息主体解析状态
如果是GET请求 ,那么请求内容长度为0 ,主状态机不需要转移到CHECK_STATE_CONTENT状态,直接执行do_request响应报文就行
如果是POST请求 ,那么请求内容长度不为0 ,主状态机需要被触发转移到CHECK_STATE_CONTENT状态,结束主状态机中请求头的解析状态 ,转为解析请求内容获取请求内容中的数据(用户名和密码)
Host:请求的主机名,用于判断请求的资源是哪个主机的
本项目中只有一个主机(采用回环IP127.0.0.1),所以不需要判断
其中代码中要注意m_linger变量是用于返回响应报文时 添加对应的Connection字段的值的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 http_conn::HTTP_CODE http_conn::parse_headers (char *text) if (text[0 ] == '\0' ){ if (m_content_length != 0 ){ m_check_state = CHECK_STATE_CONTENT; return NO_REQUEST; } return GET_REQUEST; } else if (strncasecmp (text, "Connection:" , 11 ) == 0 ) { text += 11 ; text += strspn (text, " \t" ); if (strcasecmp (text, "keep-alive" ) == 0 ) { m_linger = true ; } } else if (strncasecmp (text, "Content-length:" , 15 ) == 0 ) { text += 15 ; text += strspn (text, " \t" ); m_content_length = atol (text); } else if (strncasecmp (text, "Host:" , 5 ) == 0 ) { text += 5 ; text += strspn (text, " \t" ); m_host = text; } else { } return NO_REQUEST; }
4.3 解析请求内容
请求内容的解析比较简单,只要根据Content-Length字段的值判断是否已经读完了完整的HTTP消息体,然后将消息体内容存放在m_string中用于后面do_request的账号密码处理即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 http_conn::HTTP_CODE http_conn::parse_content (char *text) if (m_read_idx >= (m_content_length + m_checked_idx)) { text[m_content_length] = '\0' ; m_string = text; return GET_REQUEST; } return NO_REQUEST; }
五、报文响应
5.1
do_request函数解析请求资源路径
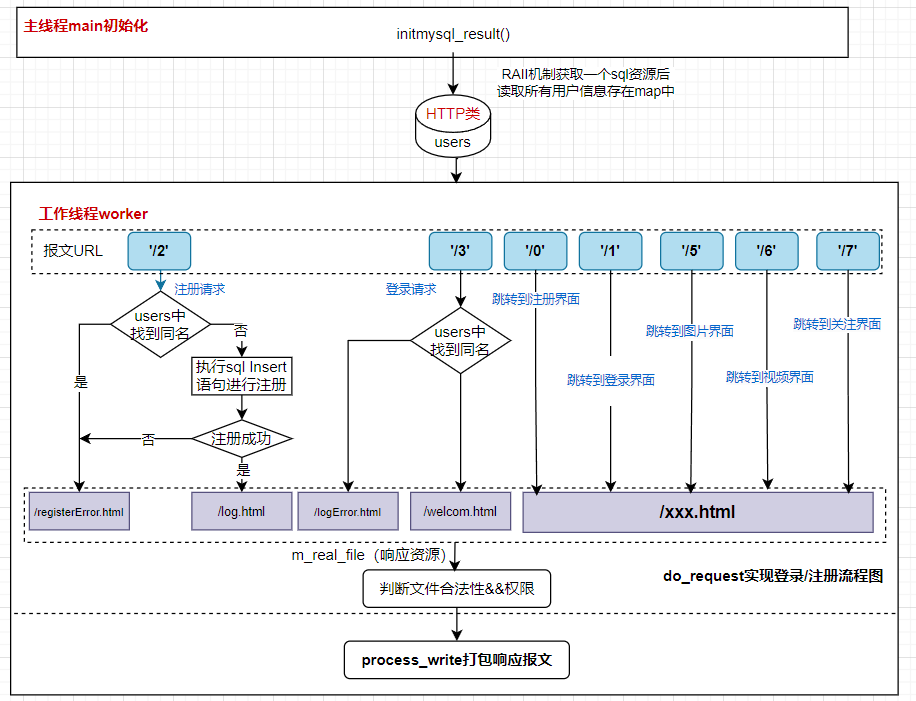
由于do_request需要对用户名和密码进行处理,本项目为了减少对数据库的频繁访问,在main.cpp初始化程序时就将数据库中的所有用户名和密码都读取出来,存放在usersmap表中,若需要比对则直接跳过users.find()匹配查询即可
在do_request中需要将WebServer类中初始化的root路径和http_conn类中解析的URL路径拼接起来,形成完整的m_real_file资源路径,然后根据资源路径的不同进行不同的处理。
从4.1
解析请求行 中可知,本项目请求资源路径的响应共有8种情况。
其中对于注册 ,需要先判断用户名是否已存在,之后再申请从数据库池 中获取一个新的数据库连接 执行插入 操作实现注册
对于登录 ,需要验证用户名和密码 ,直接users.find()匹配查询即可
对于其它资源请求 ,直接根据报文的m_url将资源路径存入m_real_file中即可
简化的do_request代码执行流程图如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 http_conn::HTTP_CODE http_conn::do_request () strcpy (m_real_file, doc_root); int len = strlen (doc_root); const char *p = strrchr (m_url, '/' ); if (cgi == 1 && (*(p + 1 ) == '2' || *(p + 1 ) == '3' )) { char flag = m_url[1 ]; char *m_url_real = (char *)malloc (sizeof char ) * 200 ); strcpy (m_url_real, "/" ); strcat (m_url_real, m_url + 2 ); strncpy (m_real_file + len, m_url_real, FILENAME_LEN - len - 1 ); free (m_url_real); char name[100 ], password[100 ]; int i; for (i = 5 ; m_string[i] != '&' ; ++i) name[i - 5 ] = m_string[i]; name[i - 5 ] = '\0' ; int j = 0 ; for (i = i + 10 ; m_string[i] != '\0' ; ++i, ++j) password[j] = m_string[i]; password[j] = '\0' ; if (*(p + 1 ) == '3' ) { char *sql_insert = (char *)malloc (sizeof char ) * 200 ); strcpy (sql_insert, "INSERT INTO user(username, passwd) VALUES(" ); strcat (sql_insert, "'" ); strcat (sql_insert, name); strcat (sql_insert, "', '" ); strcat (sql_insert, password); strcat (sql_insert, "')" ); if (users.find (name) == users.end ()) { m_lock.lock (); int res = mysql_query (mysql, sql_insert); users.insert (pair<string, string>(name, password)); m_lock.unlock (); if (!res) strcpy (m_url, "/log.html" ); else strcpy (m_url, "/registerError.html" ); } else strcpy (m_url, "/registerError.html" ); } else if (*(p + 1 ) == '2' ) { if (users.find (name) != users.end () && users[name] == password) strcpy (m_url, "/welcome.html" ); else strcpy (m_url, "/logError.html" ); } } if (*(p + 1 ) == '0' ) { char *m_url_real = (char *)malloc (sizeof char ) * 200 ); strcpy (m_url_real, "/register.html" ); strncpy (m_real_file + len, m_url_real, strlen (m_url_real)); free (m_url_real); } else if (*(p + 1 ) == '1' ) { char *m_url_real = (char *)malloc (sizeof char ) * 200 ); strcpy (m_url_real, "/log.html" ); strncpy (m_real_file + len, m_url_real, strlen (m_url_real)); free (m_url_real); } else if (*(p + 1 ) == '5' ) { char *m_url_real = (char *)malloc (sizeof char ) * 200 ); strcpy (m_url_real, "/picture.html" ); strncpy (m_real_file + len, m_url_real, strlen (m_url_real)); free (m_url_real); } else if (*(p + 1 ) == '6' ) { char *m_url_real = (char *)malloc (sizeof char ) * 200 ); strcpy (m_url_real, "/video.html" ); strncpy (m_real_file + len, m_url_real, strlen (m_url_real)); free (m_url_real); } else if (*(p + 1 ) == '7' ) { char *m_url_real = (char *)malloc (sizeof char ) * 200 ); strcpy (m_url_real, "/fans.html" ); strncpy (m_real_file + len, m_url_real, strlen (m_url_real)); free (m_url_real); } else strncpy (m_real_file + len, m_url, FILENAME_LEN - len - 1 ); if (stat (m_real_file, &m_file_stat) < 0 ) return NO_RESOURCE; if (!(m_file_stat.st_mode & S_IROTH)) return FORBIDDEN_REQUEST; if (S_ISDIR (m_file_stat.st_mode)) return BAD_REQUEST; int fd = open (m_real_file, O_RDONLY); m_file_address = (char *)mmap (0 , m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0 ); close (fd); return FILE_REQUEST; }
其中do_request函数中的mmap函数是将资源文件映射到内存中,提高文件的访问速度,这样就不需要每次请求都去读取文件,而是直接从内存中读取,提高了文件的访问速度。关于mmap的介绍将在下面进行报文响应打包时详细说明
5.2 打包响应报文
5.2.1 请求报文处理的8种结果
NO_REQUEST
请求不完整,需要继续读取请求报文数据
跳转主线程继续监测读事件
GET_REQUEST
获得了完整的HTTP请求
调用do_request完成请求资源映射
NO_RESOURCE
请求资源不存在
跳转process_write完成响应报文
BAD_REQUEST
HTTP请求报文有语法错误或请求资源为目录
跳转process_write完成响应报文
FORBIDDEN_REQUEST
请求资源禁止访问,没有读取权限
跳转process_write完成响应报文
FILE_REQUEST
请求资源可以正常访问
跳转process_write完成响应报文
INTERNAL_ERROR
服务器内部错误,该结果在主状态机逻辑switch的default下,一般不会触发
使用process_write函数进行响应报文打包时,将会根据这8种结果封装不同的格式化字符串到报文 中
5.2.2
http_conn类中的process_write函数
工作线程中process_write根据do_request的请求解析结果(8种状态),通过5个相关函数 逐个进行响应报文的打包,最后在工作线程中将http_conn用户对应的socketfd注册到epoll中,监听写事件,等待下一次写事件触发,完成响应报文的发送。
通过iovec结构体将多个非连续的内存区域组合在一起(以便在epoll写事件触发时,一次性的I/O操作将内存数据writev写入socketfd中发送给客户端)。
iovec结构体中的iov_base指向内存区域的起始地址iov_len指明内存区域的长度
本项目中,iovec结构体的m_iv数组中存放了两个iovec结构体,分别指向m_write_buf和m_file_address
如果请求报文处理结果是FILE_REQUEST状态,代表请求的文件资源是可以正常访问的,所以会把响应资源m_file_address也添加到m_iv数组中作为响应报文的响应体
如果请求报文处理结果是GET_REQUEST状态,代表请求的文件资源是空的,生成一个空的html文件(ok_string)返回
如果请求报文处理结果是其它状态,只申请一个buff的iovec,将m_write_buf添加到m_iv数组中,报文响应体 调用add_content函数直接添加格式化的字符串 到m_write_buf中,不需要第二个iovec
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 bool http_conn::process_write (HTTP_CODE ret) switch { case INTERNAL_ERROR: { add_status_line (500 , error_500_title); add_headers (strlen (error_500_form)); if (!add_content (error_500_form)) return false ; break ; } case BAD_REQUEST: { add_status_line (404 , error_404_title); add_headers (strlen (error_404_form)); if (!add_content (error_404_form)) return false ; break ; } case FORBIDDEN_REQUEST: { add_status_line (403 , error_403_title); add_headers (strlen (error_403_form)); if (!add_content (error_403_form)) return false ; break ; } case FILE_REQUEST: { add_status_line (200 , ok_200_title); if (m_file_stat.st_size != 0 ) { add_headers (m_file_stat.st_size); m_iv[0 ].iov_base = m_write_buf; m_iv[0 ].iov_len = m_write_idx; m_iv[1 ].iov_base = m_file_address; m_iv[1 ].iov_len = m_file_stat.st_size; m_iv_count = 2 ; bytes_to_send = m_write_idx + m_file_stat.st_size; return true ; } else { const char *ok_string = "<html><body></body></html>" ; add_headers (strlen (ok_string)); if (!add_content (ok_string)) return false ; } } default : return false ; } m_iv[0 ].iov_base = m_write_buf; m_iv[0 ].iov_len = m_write_idx; m_iv_count = 1 ; bytes_to_send = m_write_idx; return true ; }
5.2.3
实现process_write的各行报文打包函数
add_response:更新m_write_idx指针和缓冲区m_write_buf中的内容,将字符串写入缓冲区
采用可变参函数 ,向缓冲区写入格式化字符串
用va_list va_start
va_end来实现变参的列表处理
用vsprintf将格式化的字符串写入缓冲区(m_write_buf)中
add_status_line:添加状态行 ,即HTTP版本号、状态码、状态码描述
add_headers:添加消息报头和空行
Content-Length字段:Content-Length: 78443Connection字段:Connection: keep-alive空行:
add_content:添加响应体
将content中的内容添加到m_write_buf中
其中,状态行 下的状态码 有以下几种:
200:请求成功
400:请求报文语法有错
403:禁止访问
404:请求资源不存在
500:服务器内部错误
1 2 3 4 5 const char *ok_200_title = "OK" ;const char *error_400_title = "Bad Request" ;const char *error_403_title = "Forbidden" ;const char *error_404_title = "Not Found" ;const char *error_500_title = "Internal Error" ;
响应体 的内容有以下几种(只针对请求处理错误的情况,请求资源可访问的情况会返回对应的文件资源而不是这种格式化字符串):
error_400_form:请求报文语法有错
error_403_form:禁止访问
error_404_form:请求资源不存在
error_500_form:服务器内部错误
1 2 3 4 const char *error_400_form = "Your request has bad syntax or is inherently impossible to staisfy.\n" ;const char *error_403_form = "You do not have permission to get file form this server.\n" ;const char *error_404_form = "The requested file was not found on this server.\n" ;const char *error_500_form = "There was an unusual problem serving the request file.\n" ;
1. add_response
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 bool http_conn::add_response (const char *format, ...) if (m_write_idx >= WRITE_BUFFER_SIZE) return false ; va_list arg_list; va_start (arg_list, format); int len = vsnprintf (m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list); if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_idx)) { va_end (arg_list); return false ; } m_write_idx += len; va_end (arg_list); return true ; }
2. add_status_line
1 2 3 4 5 6 bool http_conn::add_status_line (int status, const char *title) return add_response ("%s %d %s\r\n" , "HTTP/1.1" , status, title); }
3. add_headers
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 bool http_conn::add_headers (int content_len) return add_content_length (content_len) && add_linger () && add_blank_line (); } bool http_conn::add_content_length (int content_len) return add_response ("Content-Length:%d\r\n" , content_len); } bool http_conn::add_linger () return add_response ("Connection:%s\r\n" , (m_linger == true ) ? "keep-alive" : "close" ); } bool http_conn::add_blank_line () return add_response ("%s" , "\r\n" ); }
4. add_content
1 2 3 4 5 bool http_conn::add_content (const char *content) return add_response ("%s" , content); }
5.3
注册epoll写事件发送响应报文
服务器工作线程在process_write函数中完成解析请求报文process_read 、生成响应报文process_write 一系列操作后,在process函数中将http_conn用户对应的socketfd注册到epoll中,监听写事件,等待下一次写事件触发,写事件触发后,调用http_conn类中的write函数,最终将报文发送给客户端。(Reactor模式 下write函数在工作线程中执行的,Proactor模式 下write函数在主线程中执行的)
在发送完报文后,如果HTTP的连接属于长连接,那么就继续监听读事件,等待下一次读事件触发;如果HTTP的连接属于短连接,在webserver类或者工作线程中结束write后会调用deal_timer中timer的cb_func函数关闭客户端连接
write函数:将缓冲区中的数据通过epoll事件监听发送给客户端
该函数具体逻辑如下:
在生成响应报文时初始化byte_to_send,包括头部信息和文件数据大小。通过writev函数循环发送响应报文数据
若writev单次发送成功,更新byte_to_send和byte_have_send的大小,若响应报文整体发送成功,则取消mmap映射,并判断是否是长连接.
长连接重置http类实例,注册读事件,不关闭连接,
短连接直接关闭连接
若writev单次发送不成功,判断是否是写缓冲区满了。
若不是因为缓冲区满了而失败,取消mmap映射
若eagain则满了,更新iovec结构体的指针和长度,并注册写事件,等待下一次写事件触发(当写缓冲区从不可写变为可写,触发epollout),因此在此期间无法立即接收到同一用户的下一请求,但可以保证连接的完整性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 bool http_conn::write () int temp = 0 ; if (bytes_to_send == 0 ) { modfd (m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode); init (); return true ; } while (1 ) { temp = writev (m_sockfd, m_iv, m_iv_count); if (temp < 0 ) { if (errno == EAGAIN) { modfd (m_epollfd, m_sockfd, EPOLLOUT, m_TRIGMode); return true ; } unmap (); return false ; } bytes_have_send += temp; bytes_to_send -= temp; if (bytes_have_send >= m_iv[0 ].iov_len) { m_iv[0 ].iov_len = 0 ; m_iv[1 ].iov_base = m_file_address + (bytes_have_send - m_write_idx); m_iv[1 ].iov_len = bytes_to_send; } else { m_iv[0 ].iov_base = m_write_buf + bytes_have_send; m_iv[0 ].iov_len = m_iv[0 ].iov_len - bytes_have_send; } if (bytes_to_send <= 0 ) { unmap (); modfd (m_epollfd, m_sockfd, EPOLLIN, m_TRIGMode); if (m_linger) { init (); return true ; } else { return false ; } } } return false ; }
六、浅聊一下mmap延申的内存映射问题
经过最后epoll监听写事件,我们的完整客户端请求-响应流程就结束了。但是在响应报文生成的过程中,我们提到了mmap,这里我们简单聊一下mmap。
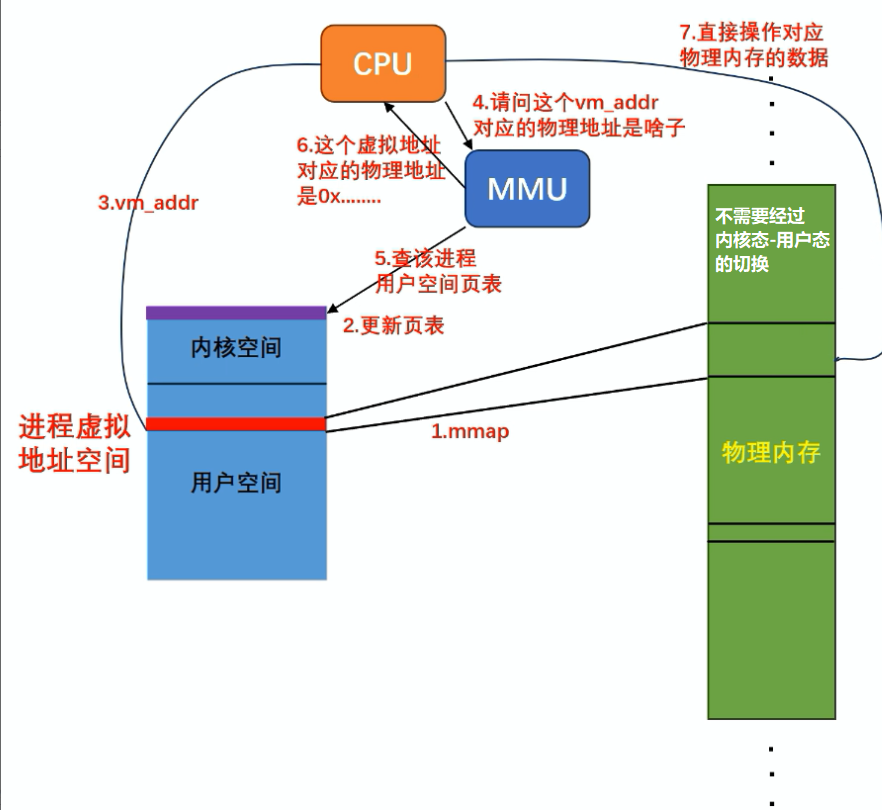
mmap是一种内存映射文件的方法,它可以将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中的一段地址的一一对应关系。这样,进程就可以采用指针的方式读写文件,而且可以实现进程间的文件共享。说到这,我们就先得来了解一下什么是虚拟内存 ,什么是物理内存和驻留内存 。
mmap的操作流程如下所示:
如图所示,使用mmap与普通的通过中断+系统调用 进行I/O文件阻塞读写的区别在于,mmap是通过内存映射 的方式将文件通过映射到虚拟内存 中,然后通过页表 将虚拟内存映射到物理内存 中,这样可以不经过用户态和内核态的切换 ,直接通过指针 访问文件,提高了I/O的效率。
6.1
虚拟内存vs物理内存和驻留内存
虚拟内存
虚拟内存是操作系统为了对进程地址进行管理而设计的逻辑上的内存空间 ,比如我们编写一个C++程序,采用g++编译 的时候编译器处理各种指针、变量等采用的就是虚拟内存 ,因为此时程序还未运行,不可能直接访问物理内存。虚拟内存是连续的 ,是逻辑上的 ,是抽象的 ,是不受物理内存大小限制 的。
所以程序运行过程中用到的指令、代码、数据都必须存在于虚拟内存中。虚拟内存的存在解放了物理内存的大小限制。
物理内存
物理内存是指实实在在的RAM内存上的空间 ,虚拟内存中的程序在物理机器上运行时,通过页映射表 将虚拟内存中的地址映射到物理内存中的地址,从而真正实现程序运行。
虚拟内存向物理内存的映射是按需映射 的,因为虚拟内存很大,可能有一部分程序在运行中根本不需要访问到,所以映射时只会讲访问到的部分映射到物理内存中。当需要访问另一部分程序时再将其映射到物理内存中(在触发缺页中断 时利用分页技术 将实际的物理内存分配给虚拟内存),所以一个程序运行时在虚拟内存中是碎片化 存在的(不连续)。
驻留内存
驻留内存是指已经映射到物理内存中的虚拟内存 ,是实实在在存在于物理内存 中的。
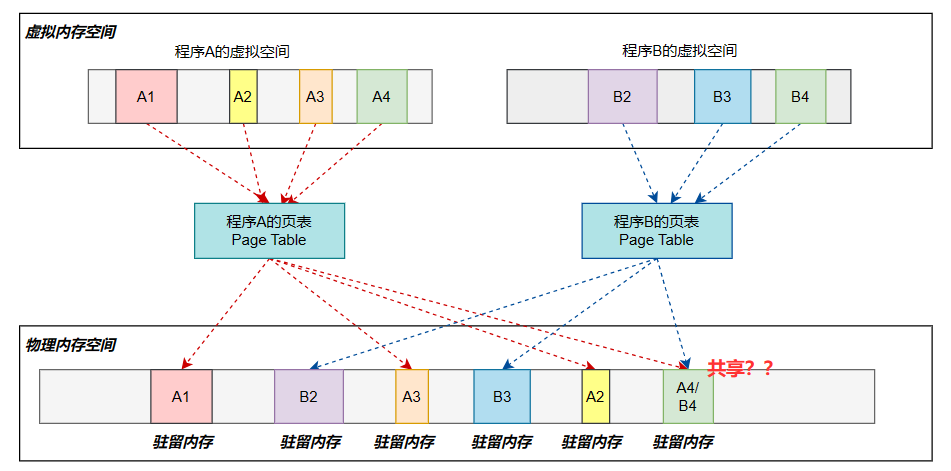
6.2 图解三种内存的关联
以下面的图为例,灰色 代表运行程序中未被访问的部分(没被映射到物理内存中);彩色 代表运行程序中被访问的部分在虚拟内存和物理内存中的映射关系。
通过上图可以直观感受到一个程序在虚拟内存 上是连续 的,运行时在物理内存是按需映射 后碎片化 存在的。也可以得到虚拟内空间大只能表示程序运行过程中可访问的空间比较大,不代表物理内存空间占用也大 的结果。
但是我们可以发现一个很奇怪的现象,为什么程序A中的A4和程序B中的B4映射到了同一块物理内存中 呢?其实这就涉及内存共享 的概念,也就是说程序A和程序B中的一部分数据或代码是共享的,这样可以节省物理内存的使用。
6.3 内存共享
程序共享内存主要存在于以下几种情况
共享库 :多个程序使用相同的库,操作系统可以把这些库加载到内存中的一块区域,这样只用维护一块内存空间
父子进程 :父子进程之间可以通过共享内存 进行通信,这样可以减少进程间通信的开销,使他们共同读写一块内存区域
内存映射文件 :操作系统可以将文件映射到进程的虚拟内存中,本项目中使用的mmap就是这种方式,将文件映射到进程的虚拟内存中,这样可以减少文件拷贝到内存的开销,提高I/O读取效率
进程A和进程B都映射了区域C,当A第一次读取C时通过缺页从磁盘复制文件页到内存中;但当B再读C的相同页面时,虽然也会产生缺页异常,但是不再需要从磁盘中复制文件过来,而可直接使用已经保存在内存中的文件数据。
6.4 从C++的角度深入理解内存映射
6.4.1 C++内存分区
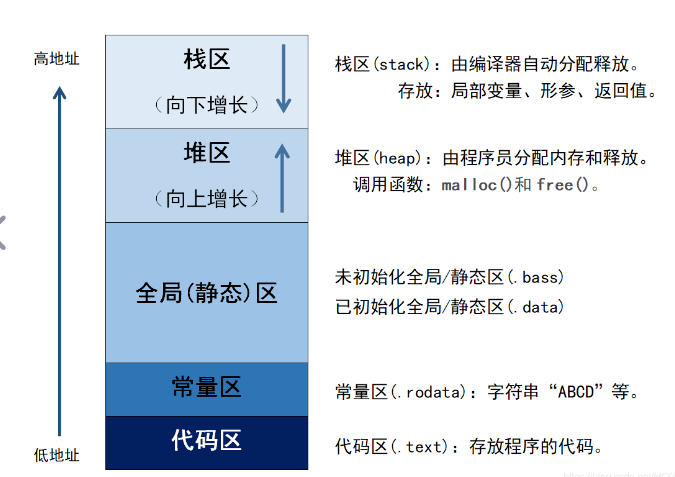
C++的代码存于虚拟内存中,C++内存主要分为栈区 、堆区 、全局/静态区 、常量区 和代码区 五个区。
栈区 :由编译器自动分配释放,存放函数的实参值 、局部变量 的值等,栈上的变量⽣命周期与其所在函数的执⾏周期相同。由编译器负责自动分配和释放。(先进后出)堆区 :由程序员分配释放 ,若程序员不释放,程序结束时由操作系统回收,堆上的变量⽣命周期由程序员显式控制。在C++中可以分配(使⽤
new 或 malloc )和释放(使⽤ delete 或 free )。(先进先出)全局/静态区 :存放全局变量、静态变量 ,程序一经编译 这些变量就会存在,程序结束后由操作系统释放。常量区 :存放常量字符串 ,程序结束后由操作系统释放。代码区 :存放函数体的二进制代码 。
其中栈(stack)的内存地址是向下增长的,堆(heap)的内存地址是向上增长的
所以我们平时所说的代码的运行,分配,操作 等,都是指的虚拟内存 !!!!!!!!
程序申请和操作 的内存都是在虚拟内存 上的,包括堆(heap) 、栈(stack) 等。
6.4.2 内存的延迟分配
前面提到虚拟内存中,其实就属于延迟分配 ,Linux内核在用户申请内存时(比如malloc和new),只是先给它分配在虚拟内存 中,并不分配实际的物理内存。
只有当用户使用这块内存 时(比如赋值、读取等),才会触发缺页中断 ,内核才会分配具体的物理页面 给用户,此时才占用宝贵的物理内存。
内核释放物理页面是通过虚拟内存找到对应的物理页面 ,然后释放物理页面,但是虚拟内存中的映射关系不会立即释放,只有当用户再次访问这块内存时,才会触发缺页中断 ,重新分配物理页面。
1 2 3 char *p=malloc (2048 );strcpy (p,"123" ); free (p);
6.4.3 内存空洞问题
一个场景,我们知道C++中堆是从下往上的,而堆又是先进先出的,所以当堆顶申请的物理内存还在使用时中 ,如果底下有些内存块被释放了,那么这些释放的物理内存就不会返回到系统中 ,形成了内存空洞 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <stdlib.h> #include <stdio.h> #include <string.h> #include <unistd.h> int main () char *p[11 ]; int i; for (i=0 ;i<10 ;i++) { p[i]=(char *)malloc (1024 *2 ); strcpy (p[i],"123" ); } p[10 ]=(char *)malloc (1024 *2 ); strcpy (p[10 ],"123" ); for (i=0 ;i<10 ;i++) { free (p[i]); } pid_t pid=getpid (); printf ("pid:%d\n" ,pid); pause (); return 0 ; }
经过上面的代码,如果没有内存空洞,那么此时进程应该只是占用了一个物理页面,剩下堆顶一个2k
但是通过查看memmap命令,我们可以看到1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0,说明堆顶的2k内存还在使用,但是底下的10个2k内存已经被释放,但是并没有返回给系统,这就是内存空洞 。
6.4.4 mmap的内存映射
最后经过前面基础知识的铺垫,我们再来聊一下mmap的优点:
减少I/O操作 :mmap将文件映射到内存中,提高了文件的访问速度,不需要每次请求都去读取文件,而是直接从内存中读取
减少内存拷贝 :mmap将文件映射到内存中,减少了内存拷贝的次数,提高了文件的访问速度
内存共享 :mmap可以实现内存共享,多个进程可以映射同一个文件,实现进程间的文件共享
延迟分配 :mmap是按需映射的,只有在访问到文件时才会映射到内存中,减少了内存的占用
6.5 参考
详解进程的虚拟内存,物理内存,共享内存
一文理解虚拟内存、物理内存、内存分配、内存管理
七、总结
这篇博客应该是本项目最长的一篇了,而HTTP报文的实现也确实是这个项目的主体部分,所以花了比较长的篇幅,还是要好好理解一下
这里需要结合前面线程池 的相关实现以及Reactor和Proactor模式 的相关知识,才能更好地理解HTTP类实现的整个流程。还是需要好好消化一下
最后,到这里我们已经实现了HTTP服务器的基础功能了,接下来我们将会实现日志系统 、定时器 两个功能,最后再进行压力测试 ,最终完成整个项目的实现。
关于后续的学习,我们先从定时器 入手,具体内容请看下一篇博客WebServer学习7:定时器控制客户端存活时间